이번 블로그 글의 주제로는 AWS 환경에서 시스템 규모의 확장에 따른 아키텍처에 대해 글을 쓰고자 한다. 시스템 규모의 확장은 백명의 사용자에서 수백만 사용자를 지원하는 시스템 설계를 뜻한다. 그렇다면, 처음부터 수백만의 사용자를 지원하는 시스템을 설계하면 되지 않을까라고 생각되지만, 확장에 필요한 서비스들의 비용, 작업 오버헤드 및 러닝 커브때문에 추천하지 않는다. 결국 소수의 사용자에서 몇 백만으로 이르기까지의 지속적인 계랑과 끝없는 개선이 요구되는 과정이라 볼 수 있다.
그렇기 때문에 시스템 규모 확장를 이해하면 아키텍처 설계 및 이해에 큰 도움이 될 것이라 생각하며 정리한 글을 공유할 예정이다. 규모 확장을 주제로 AWS 유튜브 및 서적을 참고로 작성하였으며, 직접 실습 예제를 배포하여 규모의 확장 내용을 다룰 것이다. 또한, 컨테이너 오케스트레이션 환경인 EKS가 규모의 확장 과정에서 어떤 역할을 하는 지 살펴보겠다. 규모의 확장 환경으로는 AW 이번 글에서는 AWS 클라우드 환경 안에서를 한정하여 작성한다.
시스템 규모의 확장
100명 이상의 사용자 : 기본 3티어 아키텍처
아래 그림은 시스템 규모의 초기 시스템 아키텍처이다. 아키텍처는 DNS 서비스인 Route53 과 웹 서버, 데이터베이스으로 구성된다. 기본 통신 과정은 사용자가 Rouet53으로 도메인을 질의하여 웹 서버 IP 주소를 반환받고 통신된다.
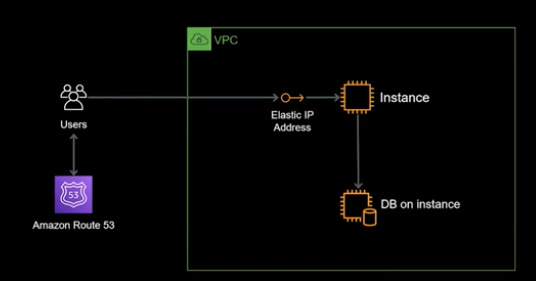
기본 시스템임에도 불구하고 수백까지의 트래픽을 감당할 수 있다. 하지만 천의 레벨로 넘어가면 어떻게 될까? 다음과 같은 고려사항이 필요하다.
- Single Point of Failure (SPOF) : 시스템 내에서 단 한 곳에서 발생한 장애가 전체 시스템의 작동을 중단시키는 구성 요소이다. 위 아키텍처 처럼 단일 서버에서 문제가 발생하면 전체 웹 서비스가 작동을 멈출 것이다. 이를 해결하기 위해 고가용성을 유지해야 한다.
- 사용자에 따른 시스템 병목 현상 및 스케일링 : 사용자가 동시에 몰리게 되면 각 레이어에서 처리량이 증가하여 속도를 저하시기고 응답 시간이 느려지게 된다. 또한, 데이터베이스에서는 많은 사용자 처리시 동시 연결 수를 초과하여 연결 요청이 거부될 수 있고, 무결성 문제가 일으킬 수 있다.
10,000명 이상의 사용자 : 이중화와 CDN 캐싱
AWS 서비스를 사용하면 위 고려사항을 모두 해결할 수 있다. AWS 의 서비스는 관리형 서비스로 이중화 기능이 제공되기 때문이다. 또한, 기능 확장 서비스를 연계하여 추가 기능을 쉽게 추가할 수 있다. 각 레이어 별로 추가한 서비는 다음과 같이 나눌 수 있다.
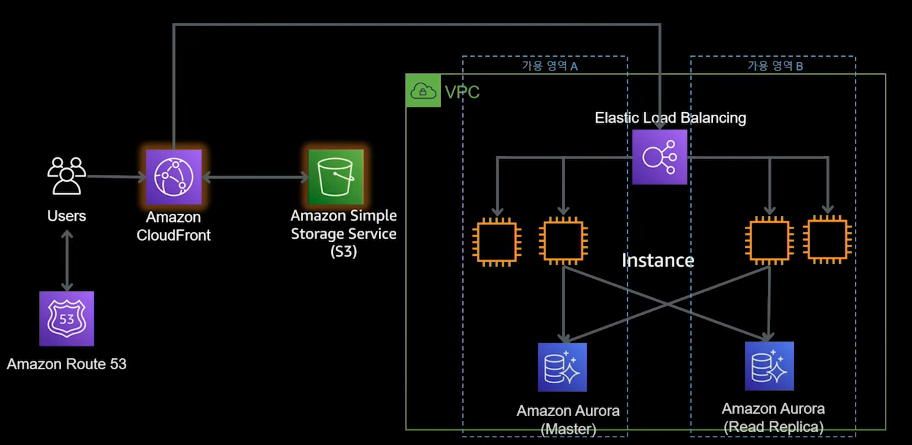
- 서버 수평 확장 : 오토스케일링을 통해 서버 수를 증가, 추가시킬 수 있는 서비스이다. 이를 통해 부하, 장애 대응, 비용 절감 효과를 부를 수 있다.
- ELB(Elastic Load Balancing) 을 통한 수평 확장 : 여러 서버가 생김에 따라 트래픽을 분산시켜야 한다. AWS에서는 트래픽 부하를 고르게 분산해주는 로드밸런싱 서비스로 ELB를 제공한다. ELB는 다중 가용 영역을 지원하며, 자동으로 용량이 확장된다. 주로 서버 수평 확장에서 사용된 오토스케일링 서비스를 연계하여 사용한다.
- RDS 을 통한 데이터베이스 이중화 : RDS는 관리형 데이터베이스 서비스로 간편한 관리, 뛰어난 확장성, 가용성 및 내구성, 성능을 가진다. 특징 중 가용성이 이중화를 뜻하는데, 다중 가용 영역에서 master-replica 구조로 운영됨을 뜻한다. RDS에서는 Aurora라는 DB가 지원되는데 샤드 스토리지 볼륨을 통해 기본 DB 엔진에 비해 뛰어난 성능 및 확장성을 제공한다.
- CloudFront & S3 를 통한 캐싱 : CloudFront 는 정적 컨텐츠를 전송하는데 쓰이는 CDN(Content Delivery Network)서비스이다. CloudFront를 통해 컨텐츠를 제공하면 사용자는 빠른 응답 시간과 서버 측에서의 과부하를 줄일 수 있다. 사용자가 컨텐츠 요청시 S3에 해당 컨텐츠가 있다면 서버를 거칠 필요없이 CloudFront에서 처리되기 때문이다.
100,000 명 이상의 사용자 : 컨테이너 서비스 전환 및 DB 성능 개선
100,000명 이상의 사용자를 가진 시스템이라면 시스템 자체의 구조 개선과 DB 성능 개선이 필요하다. 이를 위한 방법으로 컨테이너 서비스와 인메모리 DB를 활용할 수 있다.
컨테이너 서비스 전환
100,000 명 이상의 사용자가 시스템을 사용한다면 컨테이너 전환를 고려할 때이다. 컨테이너란 코드, 의존성, 런타임을 묶어서 만든 하나의 Immutable 단일 객체이다. Immutable 란 운영 중 시스템을 변경하는 것이 아니라 새로운 것으로 교체하는 것을 뜻한다. 또한, 컨테이너는 표준화 및 경량화되어 있을 뿐 아니라 이식하기 쉽고 배포 측면에서 강점을 이루기 때문에 마이크로 서비스 아키텍처를 구현하는데 필수적인 플랫폼으로 여겨진다.
AWS 에서는 이러한 컨테이너를 관리하는 오케스트레이션 서비스인 서비스를 제공한다. 각 컨테이너를 묶어 파드로 구성하며 관리 모델에 따라 여러 서버스(Fargate, EKS, ECS) 로 제공된다. 그 중 EKS 서비스는 쿠버네티스를 기반으로 하는 관리형 컨테이너 서비스로 쿠버네티스 구성 중 컨트롤 플레인을 관리한다. 다른 컨테이너 서비스와 달리 EKS는 쿠버네티스 API를 따르기 때문에 기존의 쿠버네티스 환경과 호환성을 보장하여 다른 클라우드 환경과 온-프레미스와 통합이 가능하다.
인메모리 DB를 통한 읽기 성능 개선
인메모리 DB란 데이터를 컴퓨터 메인 메모리(RAM)에 저장하여 데이터베이스보다 훨씬 빠른 성능을 제공하는 DB이다. 인메로리 DB를 당장의 아키텍처로 적용시 읽기 성능을 높일 수 있는 캐싱으로 적용할 수 있다. AWS 에서는 인메모리 데이터스토리지 서비스로 ElastiCache를 제공한다. ElastiCache 는 관리형 Memcached 및 redis 엔진을 제공하며 자동 확장성, 자가 복구, 한 자리수 ms 을 가진다. 일반적으로 캐쉬, 세션 저장소, 채팅, 게임 리더 보드등에 활용되어진다.
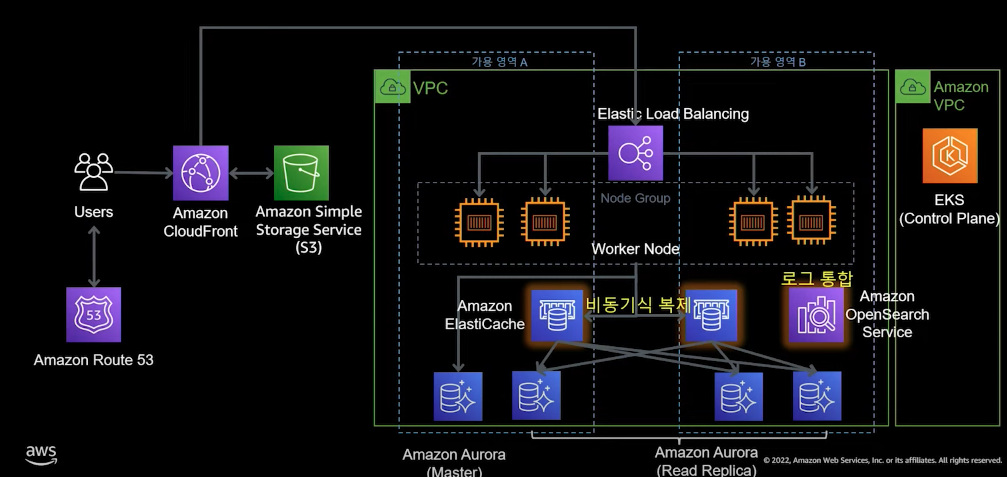
- 서버 구조가 EKS로 전환됨에 따라 로깅 통합 도구가 필요하다. 아키텍처에서는 AWS 로깅 통합 서비스인 opensearch를 사용하였다.
1,000,000 만 이상의 사용자를 넘어서 : 데이터베이스 분산 및 재해 복구, 멀티리전 서비스 구현
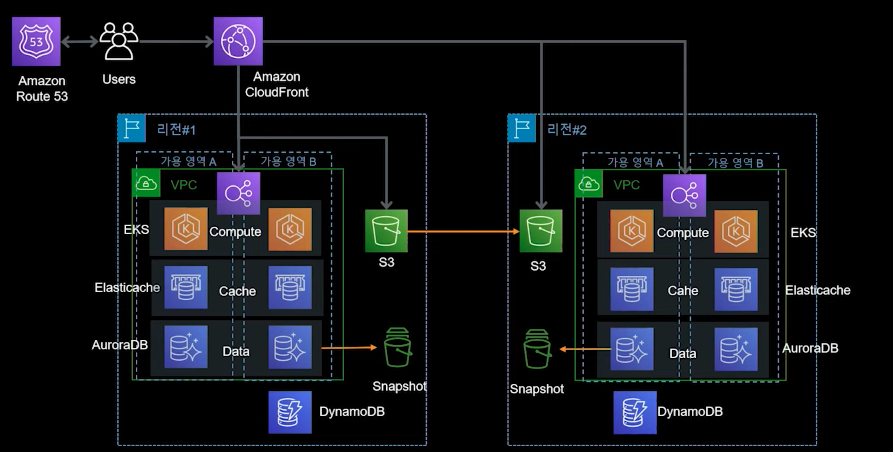
위 아키텍처를 확인하면 규모에 따라 서버가 확장되어 분산 처리되는 반면, DB는 Master에서만 쓰기를 담당하기에 기능 개선을 위해 데이터베이스 분리 및 샤딩이 필요하다. 또한, 가용성을 보장하고 데이터 손실을 예방하기 위해 재해 복구 및 멀티 리전 구성이 필요하다.
DB 분산
DB 분산 방법 중 하나로 용도에 맞는 DB 서비스를 나눠 적용시켜야 한다. AWS에서는 용도에 따라 DB 서비스를 다음과 같이 선택할 수 있다.

아래 소개할 아키텍처에서는 비관계형 DB인 DynamoDB를 사용하였는데 쓰기 작업이 많이 필요한 경우(장바구니, 위시 리스트)에 적합하기 때문에 구성하였다. DynamoDB는 대규모 요청에도 한자릿수 ms 응답시간을 보장하며, 페타라이트 규모 스토리지, 다중 리전 글로벌 테이블 복제 및 DAX 를 통한 자체 읽기 및 쓰기 캐시를 제공한다. 또한, 10,000,000 명 이상의 규모 확장시 DB 자체 내 글로벌 기능을 활성화시켜 운영하는 것을 추천한다.
재해 복구 및 멀티리전 서비스 구현
스토리지 서비스인 S3의 교차 리전 기능과 DB, 서버 스냅샷을 활용하여 멀티 리전을 구성할 수 있다. 이를 통해 리전 1에서 문제가 발생할 경우 리전 2에서 빠르게 리소스를 복구시킬 수 있다. 리소스 복구 방법은 두 가지 단계가 필요하는데 DB는 글로벌 RDS나 스냅샷으로 그외 서비스는 CDK 나 클라우드포메이션, 테라폼으로 복구 시킬 수 있다.
EKS 기반의 서비스 애플리케이션 구성
앞 장에서 소개한 아키텍처 중 100,000 단위의 사용자 규모의 MSA 아키텍처를 구현해보겠다. MSA 는 쿠버네티스 AWS 관리형 서비스인 EKS를 활용하여 구성하였다. 구성 예제는 사용자 투표 기반의 애플리케이션으로 투표 기능와 결과 화면을 제공한다. 구성 아키텍처는 다음과 같다.
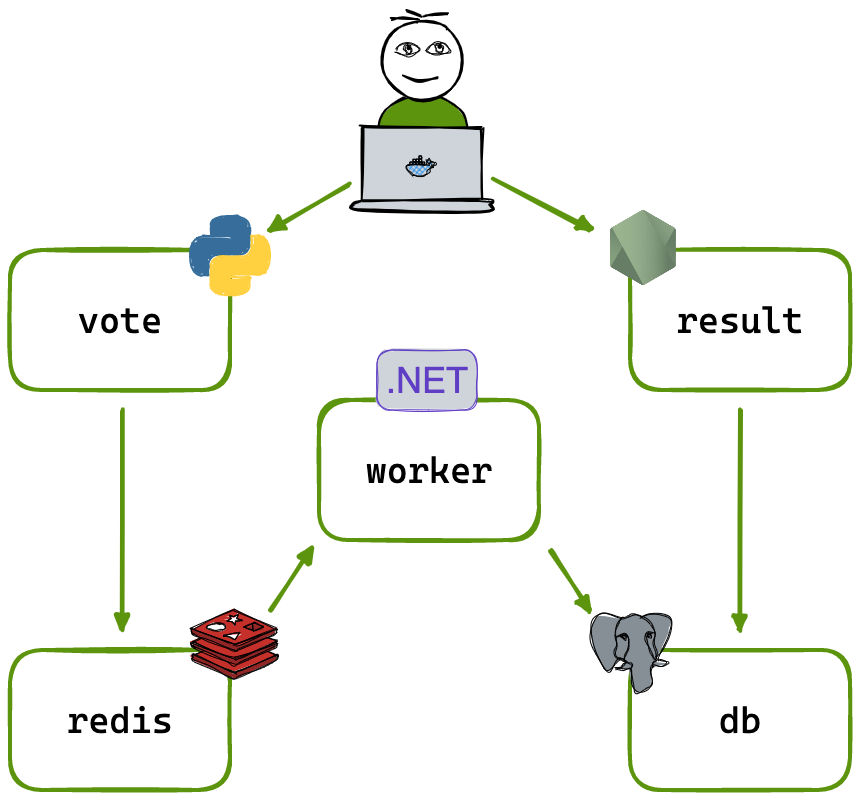
MSA 로 구성 기능이 나눠지고 언어별로 나눠진 것을 확인할 수 있다. 기능별로 구성부분을 나누자면 두 가지로 분류할 수 있다.
- Vote 출력 : DB 조회(Postgres) → result (node.js)
- Vote 입력 : work(python) → 인메모리DB(redis)→ worker(.NET) → DB(Postgres)
그럼, 예제 애플리케이션을 배포하여 연동, 구성 부분을 확인하자.
사전 작업인 EKS 구성 및 Addon 은 구성 내용이 많아 필자의 블로그 글로 대체하였다. 본 블로그 글에서는 애플리케이션 배포와 구성 부분을 살펴볼 것이다. EKS 구성과 Addon 배포는 밑의 링크를 참고하자.
- EKS 구성 : 필자 블로그 글 [AEWS] EKS 아키텍처와 Private EKS 클러스터 배포하기
- EKS addon(로드밸런싱, Route53) : 필자 블로그 글 [AEWS] EKS VPC CNI Deep Dive
EKS addon까지 구성을 완료하였으면 투표 애플리케이션을 배포하자.
|
|
애플리케이션 배포 후 입력한 도메인에서 기능을 확인할 수 있다.
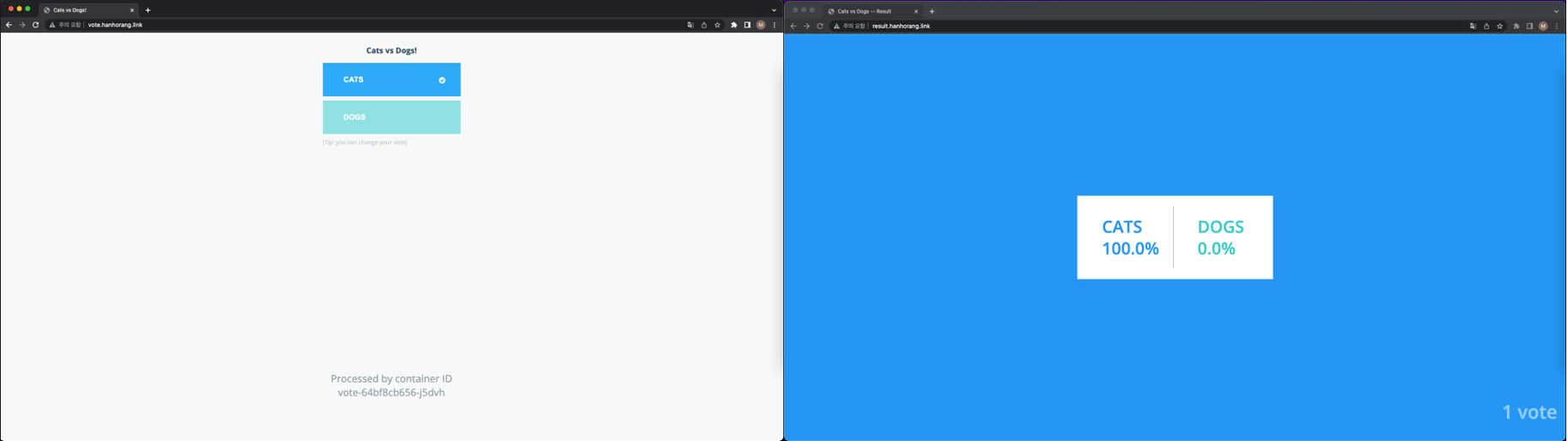
투표 입력과 투표 결과가 정상적으로 작동한다. 기능을 확인했으니, 기능별로 각 구성의 핵심 부분을 살펴보자
DB 구성
애플리케이션 구성시 선수 작업으로 DB 구성이 필요하다. 예제 애플리케이션에서는 PostgresDB 를 통해 DB를 구성하였다. 특별히 유심히 본 부분은 DB 스키마를 서비스 배포시 자동적으로 구성하도록 진행하였는데, 매니페스트파일에서도 확인할 수 없어 코드 레벨까지 살펴보았다.
|
|
PostgresDB 배포시 기본 DB만 배포되었다. 테이블 구성 부분을 찾아보자.
테이블 구성 부분은 데이터 입력 구성 서비스인 .NET에서 DB 연결 및 스키마를 구성하였다. DB 연결 함수의 코드는 다음과 같다.
|
|
-
DB 연결은 C#의 Npgsql 라이브러리를 통해 연결하였다. 함수 호출의 매개변수는 다음과 같이 string 값을 넣어서 진행하였다.
1var pgsql = OpenDbConnection("Server=db;Username=postgres;Password=postgres;"); -
예제 애플리케이션이라 DB 정보가 하드코딩되어 있다. 실제 애플리케이션에서는 쿠버네티스 시크릿이나 키 관리 서비스를 활용해야 한다.
Vote 결과 출력
DB 조회(Postgres) → result (node.js) 연동 부분이다.
살펴볼 것은 Vote 조회 부분이다. node.js 내 데이터 조회 부분은 다음과 같다.
|
|
Vote 입력
예제 애플리케이션의 차별점을 확인할 수 있는 부분이다. 차별점은 인메모리 DB가 중간에 껴서 DB 과부하 분산 및 입력 성능을 올려주는 것인데, 코드 레벨로 내려가 각 연동 부분을 확인하겠다. 구성은 vote(python) → 인메모리DB(redis)→ worker(.NET) → DB(Postgres) 로 되어 있으므로 순차적으로 확인하자.
-
vote(python)
플라스크로 서버를 구성하였으며, redis 라이브러리를 통해 인메모리DB에 데이터를 전달한다. 코드 구성으로 확인해보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26# 라이브러리 from flask import Flask, render_template, request, make_response, g from redis import Redis . . # redis 연결 def get_redis(): if not hasattr(g, 'redis'): g.redis = Redis(host="redis", db=0, socket_timeout=5) return g.redis # redis 데이터 로 전송 @app.route("/", methods=['POST','GET']) def hello(): voter_id = request.cookies.get('voter_id') if not voter_id: voter_id = hex(random.getrandbits(64))[2:-1] vote = None if request.method == 'POST': redis = get_redis() vote = request.form['vote'] app.logger.info('Received vote for %s', vote) data = json.dumps({'voter_id': voter_id, 'vote': vote}) redis.rpush('votes', data) -
worker(.NET)
0.1 초마다 인메모리 DB를 읽어 싱크 작업을 진행한다음 DB로 전달한다. 여기서 데이터 쓰기시 인메모리 DB를 사용하면 쓰기 성능가 올라가고, 분산 처리로 여러 서버에서의 데이터를 전달받아 동시에 작업을 수행할 수 있다. 이를 통해 다수의 사용자가 투표시 직관적으로 결과를 바로바로 확인할 수 있을 것이다. 핵심 로직 코드는 다음과 같다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29. . while (true) { // Slow down to prevent CPU spike, only query each 100ms Thread.Sleep(100); // Reconnect redis if down if (redisConn == null || !redisConn.IsConnected) { Console.WriteLine("Reconnecting Redis"); redisConn = OpenRedisConnection("redis"); redis = redisConn.GetDatabase(); } string json = redis.ListLeftPopAsync("votes").Result; if (json != null) { var vote = JsonConvert.DeserializeAnonymousType(json, definition); Console.WriteLine($"Processing vote for '{vote.vote}' by '{vote.voter_id}'"); // Reconnect DB if down if (!pgsql.State.Equals(System.Data.ConnectionState.Open)) { Console.WriteLine("Reconnecting DB"); pgsql = OpenDbConnection("Server=db;Username=postgres;Password=postgres;"); } else { // Normal +1 vote requested UpdateVote(pgsql, vote.voter_id, vote.vote); } }- 핵심 부분은 ListLeftPopAsync 함수이다. ListLeftPopAsync 함수는 Redis 라이브러리에서 제공하는 메서드로, Redis의 리스트에서 가장 왼쪽(즉, 가장 먼저 입력된) 요소를 제거하고 그 값을 반환하는 기능이다. 비동기적으로 작동하기 때문에 쓰레드 적용이 가능하다.
끝으로
이번 글에서는 시스템 규모 확장에 초점을 맞추어 AWS 아키텍처를 확인하고, 예제 애플리케이션을 통해 100,000 규모의 사용자 애플리케이션의 아키텍처를 일부 구현하였다. 이번 시간에는 인메모리를 통해 DB 단의 성능을 챙겼지만 프론트앤드에서의 성능 이슈로 애플리케이션 운영시 CDN 연동까지 고려해야 한다.
다음 시간에는 시스템 규모 확장을 테스트하기 위해 트래픽 테스트 툴을 살펴볼 예정이다.