AWS EKS Workshop Study (=AEWS)는 EKS Workshop 실습 스터디입니다.
CloudNet@ Gasida(가시다)님이 진행하시며,공개된 AWS EKS Workshop을 기반으로 진행하고 있습니다.
스터디 5주차 시간에는 최근 핫한 노드 수명 주기 관리 솔루션인 Karpenter를 공부하였다. 타 기업 사례에서 자주 보는 주제로서 볼 때마다 시간나면 해야지 해야지.. 생각만 했었는데 이번 스터디로 계기가 되어 정리한다. 이번 블로그 글에서는 Karpenter 에 대해 중점적으로 정리하여 공유할 예정이다. 먼저 Karpenter에 대한 개념과 원리를 살펴볼 것이고, 실습으로 오버프로비저닝과 Kubeflow와 통합하여 테스트를 진행할 것이다.
Karpenter ?
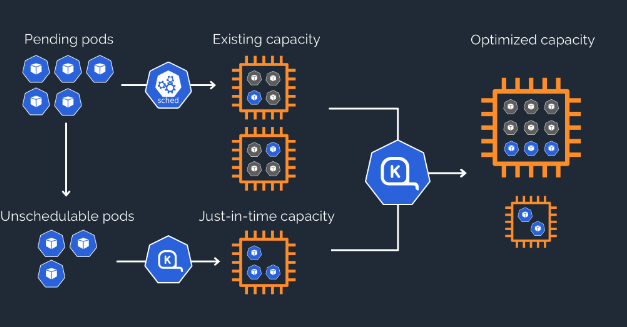
쿠버네티스에서 동작하는 오픈소스 노드 오토스케일러이다. 기존 노드 오토스케일러인 Cluster Autoscaler(CA) 의 진화 기술이라고 생각하면 생각하기 쉽겠다. CA에 비해 Karpenter 가 최근 노드 오토스케일러 기술로 각광받고 있는데 g이유를 정리하면 다음과 같다.
실시간 노드 프로비저닝(Just in time) : 기존 CA 가 5~10분 정도의 프로비저닝 시간이 걸리는 반면, Karpenter 는 5~30초 단위의 시간으로 노드가 빠르게 프로비저닝된다. 이로 인해 운영 워크로드에서 예상하지 못한 트래픽에 발 빠른 대처가 가능하다.
기능 기반 프로비저닝(Optimized) : Karpenter는 인스턴스 가드레일 방식,PV 서브넷 인식을 지원한다. 가드레일 방식이란 사용자가 지정한 인스턴스 타입의 범위에서 노드가 프로비저닝된다는 것을 의미하며 여기에서 가장 저렴한 노드를 자동으로 선택하여 프로비저닝된다. 또한, 자동으로 PV를 인식하여 PV가 존재하는 서브넷에 노드를 프로비저닝 시켜준다.
노드 자동 조정 (Optimized) : 여유 컴퓨팅 자원이 있을 시 자동으로 노드를 정리해주며, 큰 노드 하나가 작은 노드 여러개 보다 비용이 저렴하면 자동으로 합쳐줘 비용 효율적으로 노드를 운영시킬 수 있다.
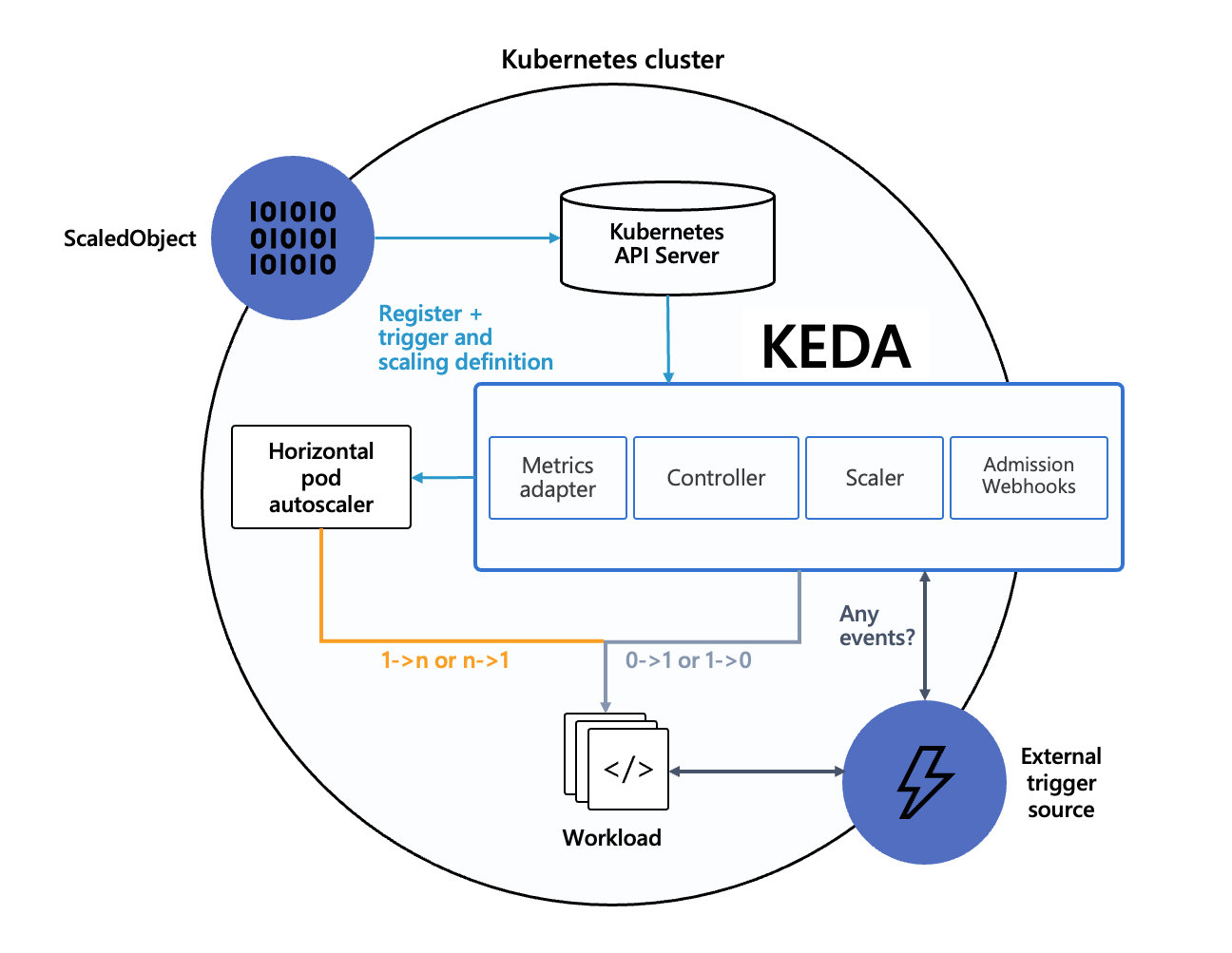
타 운영 관리 솔루션과 합쳐 다양한 노드 스케쥴링 가능 : 대표적으로 이벤트 기반의 파드 수를 조절하는 KEDA와 같이 사용하여 오버 프로비저닝이 가능하다.
기존의 EKS EC2 노드 관리를 생각하면 정말 강력한 기능이 아닐 수 없다! 기존 EKS 의 노드같은 경우 하나의 인스턴스 타입으로 노드 그룹을 구성하고 변경할 수 없었으며, 노드 프로비저닝에 기본 5분이 걸렸다.
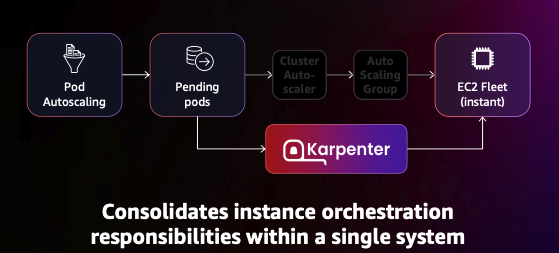
Karpenter가 이러한 기능을 제공할 수 있는 원리를 찾아보니 EKS의 노드를 노드 그룹이 아닌 EC2 Fleet으로 노드를 관리하기 때문이였다.
EC2 Fleet은 EC2 인스턴스 유형과 가용 영역을 최대한 활용하여, 비용을 최적화하는 데 유용한 도구이다. 기능적으로는 Karpenter에서 확인한 기능 요소인 다양한 인스턴스 유형 프로비저닝, Spot 인스턴스 & 온디맨드 혼합, 자동 조정을 제공한다.
Karpenter 배포
이어서 Karpenter 를 배포하고 실습해보겠다. 실습 내용은 공식문서와 스터디에서 모임장님이 공유해주신 내용을 참고하였다. 먼저 Cloudformation을 통해 베스천 서버를 구축하고 Karpenter을 활성화시키기 위해 EKS 클러스터 생성을 진행하겠다. EKS 생성이 끝나면 Karpenter을 설치하고, 예제를 통해 노드의 상태를 확인하겠다.
# 노드 그룹 서브넷 태그 추가for NODEGROUP in $(aws eks list-nodegroups --cluster-name ${CLUSTER_NAME}\
--query 'nodegroups' --output text);do aws ec2 create-tags \
--tags "Key=karpenter.sh/discovery,Value=${CLUSTER_NAME}"\
--resources $(aws eks describe-nodegroup --cluster-name ${CLUSTER_NAME}\
--nodegroup-name $NODEGROUP --query 'nodegroup.subnets' --output text )done# 보안 그룹 태그 추가 NODEGROUP=$(aws eks list-nodegroups --cluster-name ${CLUSTER_NAME}\
--query 'nodegroups[0]' --output text)LAUNCH_TEMPLATE=$(aws eks describe-nodegroup --cluster-name ${CLUSTER_NAME}\
--nodegroup-name ${NODEGROUP} --query 'nodegroup.launchTemplate.{id:id,version:version}'\
--output text | tr -s "\t"",")# If your EKS setup is configured to use only Cluster security group, then please execute -SECURITY_GROUPS=$(aws eks describe-cluster \
--name ${CLUSTER_NAME} --query "cluster.resourcesVpcConfig.clusterSecurityGroupId" --output text)# If your setup uses the security groups in the Launch template of a managed node group, then :SECURITY_GROUPS=$(aws ec2 describe-launch-template-versions \
--launch-template-id ${LAUNCH_TEMPLATE%,*} --versions ${LAUNCH_TEMPLATE#*,}\
--query 'LaunchTemplateVersions[0].LaunchTemplateData.[NetworkInterfaces[0].Groups||SecurityGroupIds]'\
--output text)aws ec2 create-tags \
--tags "Key=karpenter.sh/discovery,Value=${CLUSTER_NAME}"\
--resources ${SECURITY_GROUPS}
iam : OIDC 를 True로 설정함과 동시에 karpenter라는 쿠버네티스 서비스 어카운터에 앞 서 생성한 정책을 연결하였다. 이렇게 하면 생성한 정책에 따라 karpenter 사용자가 AWS 서비스를 관리할 수 있게 된다.
iamIdentityMappings: aws-auth configmap 업데이트 작업으로 노드 IAM 역할을 사용하는 노드가 클러스터에 가입하도록 허용시켜주는 작업이다. 예상이지만 노드를 ASG로 관리하는 것이 아닌 EC2 Fleet으로 관리하기에 추가로 필요한 작업인 것 같다.
# 카펜터 설치를 위한 환경 변수 확인exportCLUSTER_ENDPOINT="$(aws eks describe-cluster --name ${CLUSTER_NAME} --query "cluster.endpoint" --output text)"exportKARPENTER_IAM_ROLE_ARN="arn:aws:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"echo$CLUSTER_ENDPOINT$KARPENTER_IAM_ROLE_ARN# EC2 Spot Fleet 사용을 위한 정책 확인 : 이미 생성한 정책으로 결과와 같이 에러가 떠야 정상이다. aws iam create-service-linked-role --aws-service-name spot.amazonaws.com ||true--
An error occurred (InvalidInput) when calling the CreateServiceLinkedRole operation: Service role name AWSServiceRoleForEC2Spot has been taken in this account, please try a different suffix.
# public ECR 로그아웃, 익명의 상태로 이미지 다운로드하기 위함docker logout public.ecr.aws
# Karpenter 설치 helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version ${KARPENTER_VERSION} --namespace karpenter --create-namespace \
--set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=${KARPENTER_IAM_ROLE_ARN}\
--set settings.aws.clusterName=${CLUSTER_NAME}\
--set settings.aws.defaultInstanceProfile=KarpenterNodeInstanceProfile-${CLUSTER_NAME}\
--set settings.aws.interruptionQueueName=${CLUSTER_NAME}\
--set controller.resources.requests.cpu=1\
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1\
--set controller.resources.limits.memory=1Gi \
--wait
# 설치 확인 kubectl get all -n karpenter
kubectl get cm -n karpenter karpenter-global-settings -o jsonpath={.data}| jq
kubectl get crd | grep karpenter
Karpenter 모니터링 설정
Karpenter 설치가 완료되었으면 예제를 통해 노드 프로비저닝을 직접 테스트해보겠다. 먼저 노드 프로비저닝을 확인하기 위해 그라파나와 노드 모니터링 도구인 eks-node-viewer를 설치하겠다.
확장 트리거를 cron으로 설정하여 특정 시간에 확장이 발생하도록 설정하였다. 매 시간 00, 15, 30, 45분에 5개의 파드으로 확장하고, 05, 20, 35, 50분에 확장을 종료하도록 설정하였다.
🧐 ScaledObject 트러블슈팅
필자의 경우 ScaledObject 배포시 다음과 같은 스키마 에러가 발생하였다.
1
2
3
kubectl logs ScaledObject/inflate-cron-scaled -n keda
---
error: no kind "ScaledObject" is registered for version "keda.sh/v1alpha1" in scheme "pkg/scheme/scheme.go:28"
구글링하니 CRD문제라 해서 차트를 재설치하였는데 문제가 계속 되어 트러블슈팅에 시간이 걸렸다. 결론적으로 CRD문제는 아니고, ScaledObject 속한 네임스페이스(keda) 와 deployment 네임스페이스(default) 달라 생긴 문제였다. 네임스페이스를 올바르게 설정하고 배포하면 문제 없이 진행된다.
1
2
3
4
kubectl get ScaledObject -A
---
NAMESPACE NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE
default inflate-cron-scaled apps/v1.Deployment inflate 010 cron True False Unknown 9s
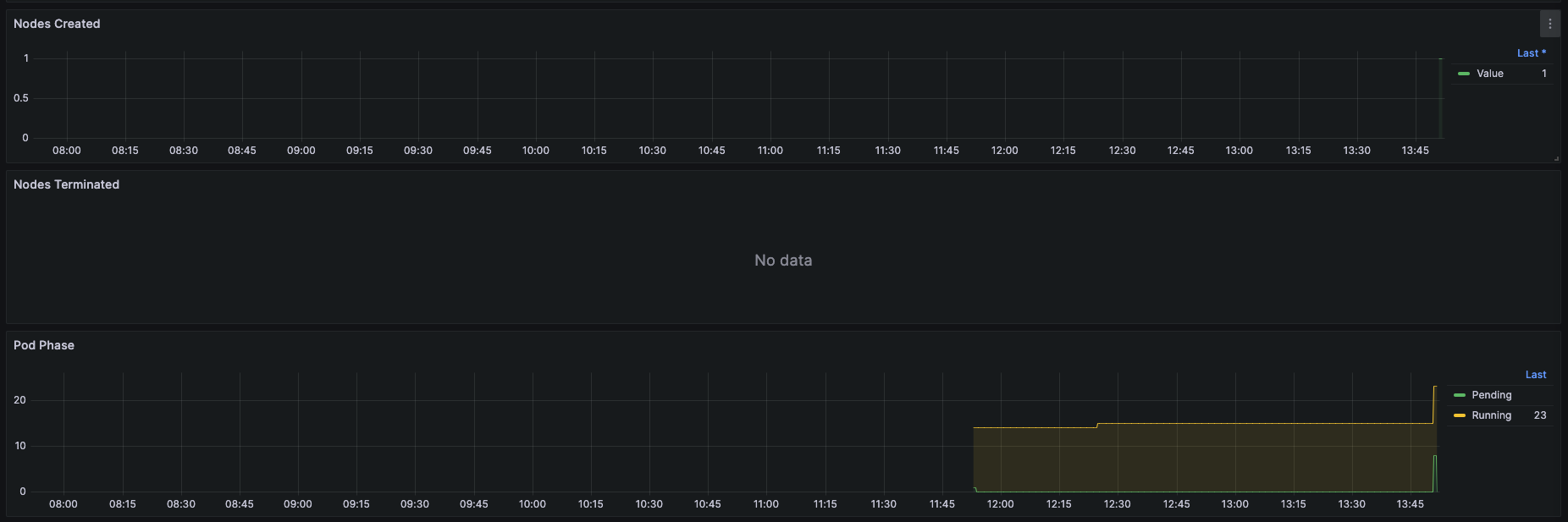
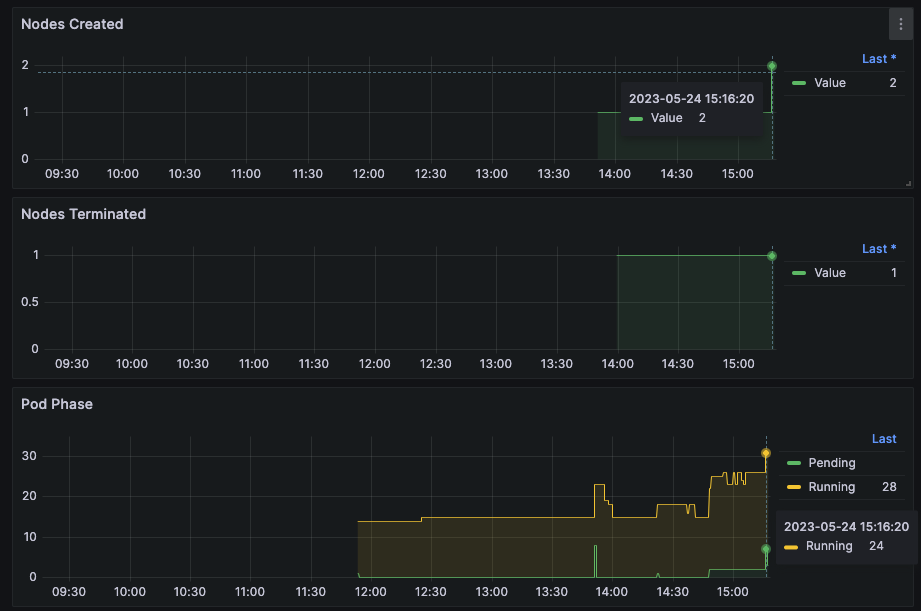
15분에 확인하니 노드가 아래와 같이 정상적으로 프로비저닝된 것을 확인할 수 있다.
Karpenter + Kubeflow 로 필요시 GPU 기반의 SPOT 인스턴스 제공하기
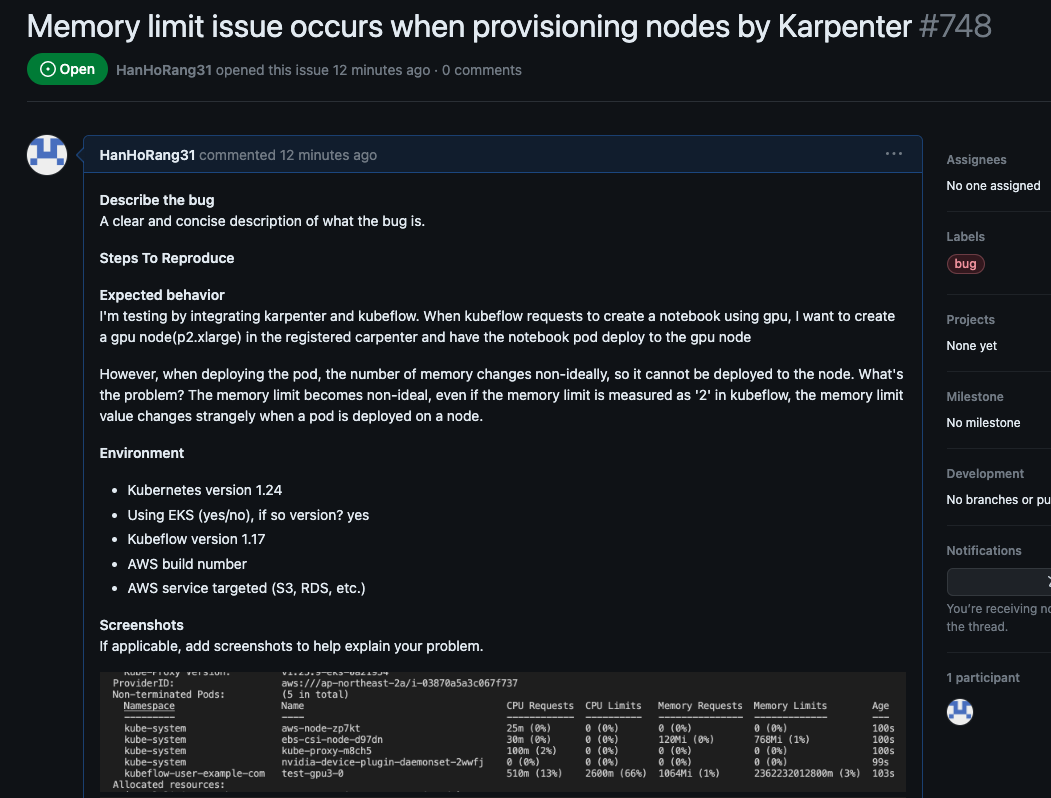
다음은 karpenter 를 kubeflow와 연계하여 GPU 기반의 SPOT 노드를 프로비저닝하겠다. 목적은 비용 최적화로 kubeflow 머신러닝 워크로드에서 GPU 자원이 필요할 때 SPOT 인스턴스를 노드에 프로비저닝하여 사용하고자 한다. 결론부터 말하면, 현재 karpenter 메모리 limit 이상 문제로 동작하지 않는다. 깃 이슈에서 문제를 확인 중이며 해결시 업데이트하겠다.
kubeflow 설치와 구성은 필자의 블로그 글을 기반으로 진행한다. karpenter를 설치하고 프로비저닝 파일은 다음과 같이 정의하여 배포한다.
# Cost-Optimized EKS cluster for Kubeflow with spot GPU instances and node scale down to zero# Built in efforts to reducing training costs of ML workloads.# Supporting tutorial can be found at the following link: # https://blog.gofynd.com/how-we-reduced-our-ml-training-costs-by-78-a33805cb00cf# This spec creates a cluster on EKS with the following active nodes # - 2x m5a.2xlarge - Accomodates all pods of Kubeflow# It also creates the following nodegroups with 0 nodes running unless a pod comes along and requests for the node to get spun up# - m5a.2xlarge -- Max Allowed 10 worker nodes# - p2.xlarge -- Max Allowed 10 worker nodes# - p3.2xlarge -- Max Allowed 10 worker nodes# - p3.8xlarge -- Max Allowed 04 worker nodes# - p3dn.24xlarge -- Max Allowed 01 worker nodesapiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
# Name of your cluster, change to whatever you find fit.# If changed, make sure to change all nodegroup tags from # 'k8s.io/cluster-autoscaler/my-eks-kubeflow: "owned"' --> 'k8s.io/cluster-autoscaler/your-new-name: "owned"' name: hanhorang
# choose your region wisely, this will significantly impact the cost incurred region: ap-northeast-2
# 1.14 Kubernetes version since Kubeflow 1.0 officially supports the same version: '1.25' tags:
# Add more cloud tags if needed for billing karpenter.sh/discovery: hanhorang
# Add all possible AZs to ensure nodes can be spun up in any AZ later on. # THIS CAN'T BE CHANGED LATER. YOU WILL HAVE TO CREATE A NEW CLUSTER TO ADD NEW AZ SUPPORT.# This list applies to the whole cluster and isn't specific to nodegroupsvpc:
id: vpc-032c30fdebbb69fd6
cidr: 192.168.0.0/16
securityGroup: sg-093be0632becd746b
nat:
gateway: HighlyAvailable
subnets:
public:
public-2a:
id: subnet-03bfdfe3c7d5aa2a4
cidr: 192.168.1.0/24
public-2c:
id: subnet-078ee0d964d71e1f2
cidr: 192.168.2.0/24
private:
private-2a:
id: subnet-0958e380d34c306e3
cidr: 192.168.3.0/24
private-2c:
id: subnet-0bd38833c317d5e2b
cidr: 192.168.4.0/24
iam:
withOIDC: true serviceAccounts:
- metadata:
name: karpenter
namespace: karpenter
roleName: hanhorang-karpenter
attachPolicyARNs:
- arn:aws:iam::955963799952:policy/KarpenterControllerPolicy-hanhorang
roleOnly: trueiamIdentityMappings:
- arn: "arn:aws:iam::955963799952:role/KarpenterNodeRole-hanhorang" username: system:node:{{EC2PrivateDNSName}} groups:
- system:bootstrappers
- system:nodes
nodeGroups:
- name: ng-1
desiredCapacity: 4 minSize: 0 maxSize: 10# Set one nodegroup with 100GB volumes for Kubeflow to get deployed. # Kubeflow requirement states 1-2 Nodes with 100GB volume attached to the node. volumeSize: 100 volumeType: gp2
instanceType: c5n.xlarge
privateNetworking: true ssh:
publicKeyName: eks-terraform-key
availabilityZones:
- ap-northeast-2a
labels:
node-class: "worker-node" tags:
# EC2 tags required for cluster-autoscaler auto-discovery k8s.io/cluster-autoscaler/node-template/label/lifecycle: OnDemand
k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot: "false" k8s.io/cluster-autoscaler/node-template/label/gpu-count: "0" k8s.io/cluster-autoscaler/enabled: "true" k8s.io/cluster-autoscaler/my-eks-kubeflow: "owned" iam:
withAddonPolicies:
awsLoadBalancerController: true autoScaler: true cloudWatch: true efs: true ebs: true externalDNS: trueaddons:
- name: vpc-cni # no version is specified so it deploys the default version version: v1.12.6-eksbuild.1
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- name: kube-proxy
version: latest # auto discovers the latest available- name: coredns
version: latest # v1.9.3-eksbuild.2
서브넷에 태그 추가
베스천 서버 구성에서 eks 클러스터를 배포함으로 서브넷과 보안 그룹에 카펜터 사용을 위한 태그가 필요하다. 다음과 같이 입력하다.
EBS CSI Driver 배포
앞 블로그 글에서의 트러블슈팅에서 다룬 내용이다. kubeflow 설치를 위해 EBS CSI driver를 배포하고 기본 스토리지 클래스를 변경하자
베스천서버 보안그룹 인그래스 규칙 추가
본 글에서는 베스천서버에서 포트포워딩을 해서 테스트한다. 이를 위해 필자는 베스천 서버의 보안 그룹 인그래스 포트 설정을 모두 허용(0.0.0.0/0)으로 바꿨다.
notebook 생성 트러블슈팅
포트포워딩으로 jupyter notebook 생성시 추가 작업이 필요하다. 아래 작업을 통해 APP_SECURE_COOKIES 옵션을 false 로 변경하자.
kubectleditdeploy/jupyter-web-app-deployment-nkubeflow---...maxUnavailable:25%type:RollingUpdatetemplate:metadata:creationTimestamp:nulllabels:app:jupyter-web-appkustomize.component:jupyter-web-appspec:containers:-env:-name:APP_PREFIXvalue:/jupyter-name:UIvalue:default-name:USERID_HEADERvalue:kubeflow-userid-name:USERID_PREFIX-name:APP_SECURE_COOKIESvalue:"false"# ture 에서 false 로 수정 ! image:docker.io/kubeflownotebookswg/jupyter-web-app:v1.7.0imagePullPolicy:IfNotPresentname:jupyter-web-appports:-containerPort:5000protocol:TCPresources:{}terminationMessagePath:/dev/termination-logterminationMessagePolicy:FilevolumeMounts:-mountPath:/etc/configname:config-volume-mountPath:/src/apps/default/static/assets/logosname:logos-volume...
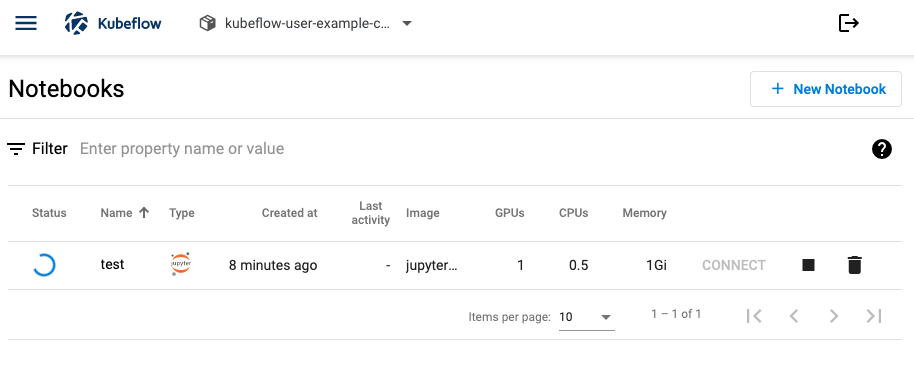
kubeflow 에서 GPU 1개를 사용하는 jupyter notebook을 생성하여 잘 동작되는 지 확인하겠다.
GPU 자원을 사용하는 jupyer notebook 생성시 파드가 pending 상태로 있다가, karpenter에 의해 GPU 노드가 새로 프로비저닝되고 파드가 배치되는 것을 확인할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# ubuntu golang install (go >1.16)wget https://go.dev/dl/go1.20.2.linux-amd64.tar.gz
sudo tar -xvf go1.20.2.linux-amd64.tar.gz
sudo mv go /usr/local
exportGOROOT=/usr/local/go
exportPATH=$GOPATH/bin:$GOROOT/bin:$PATHgo version
--
go version go1.20.2 linux/amd64
go install github.com/awslabs/eks-node-viewer/cmd/eks-node-viewer@latest
tree ~/go/bin
cd ~/go/bin
./eks-node-viewer -resources cpu,memory
🧐 워크로드 트러블슈팅
그러나, 노드의 임시 저장 공간이 부족하여 파드가 배치되었다가 추방되는 과정이 반복된다. 이벤트 로그를 확인하면 노드 ephemeral-storage 가 부족하다는데..
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 3m16s default-scheduler 0/5 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/disk-pressure: }, 4 Insufficient nvidia.com/gpu. preemption: 0/5 nodes are available: 1 Preemption is not helpful for scheduling, 4 No preemption victims found for incoming pod.
Normal Nominated 3m12s karpenter Pod should schedule on node: ip-192-168-3-68.ap-northeast-2.compute.internal
Normal Scheduled 117s default-scheduler Successfully assigned kubeflow-user-example-com/test-0 to ip-192-168-3-68.ap-northeast-2.compute.internal
Normal SuccessfulAttachVolume 113s attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-e503cf70-748c-4a9c-aef8-c94172aa2324" Normal Pulling 106s kubelet Pulling image "docker.io/istio/proxyv2:1.16.0" Normal Pulled 99s kubelet Successfully pulled image "docker.io/istio/proxyv2:1.16.0" in 7.047356094s (7.047411717s including waiting) Normal Created 99s kubelet Created container istio-init
Normal Started 99s kubelet Started container istio-init
Normal Pulling 92s kubelet Pulling image "public.ecr.aws/kubeflow-on-aws/notebook-servers/jupyter-tensorflow:2.12.0-cpu-py310-ubuntu20.04-ec2-v1.0" Warning Evicted 17s kubelet The node was low on resource: ephemeral-storage.
Warning ExceededGracePeriod 7s kubelet Container runtime did not kill the pod within specified grace period.
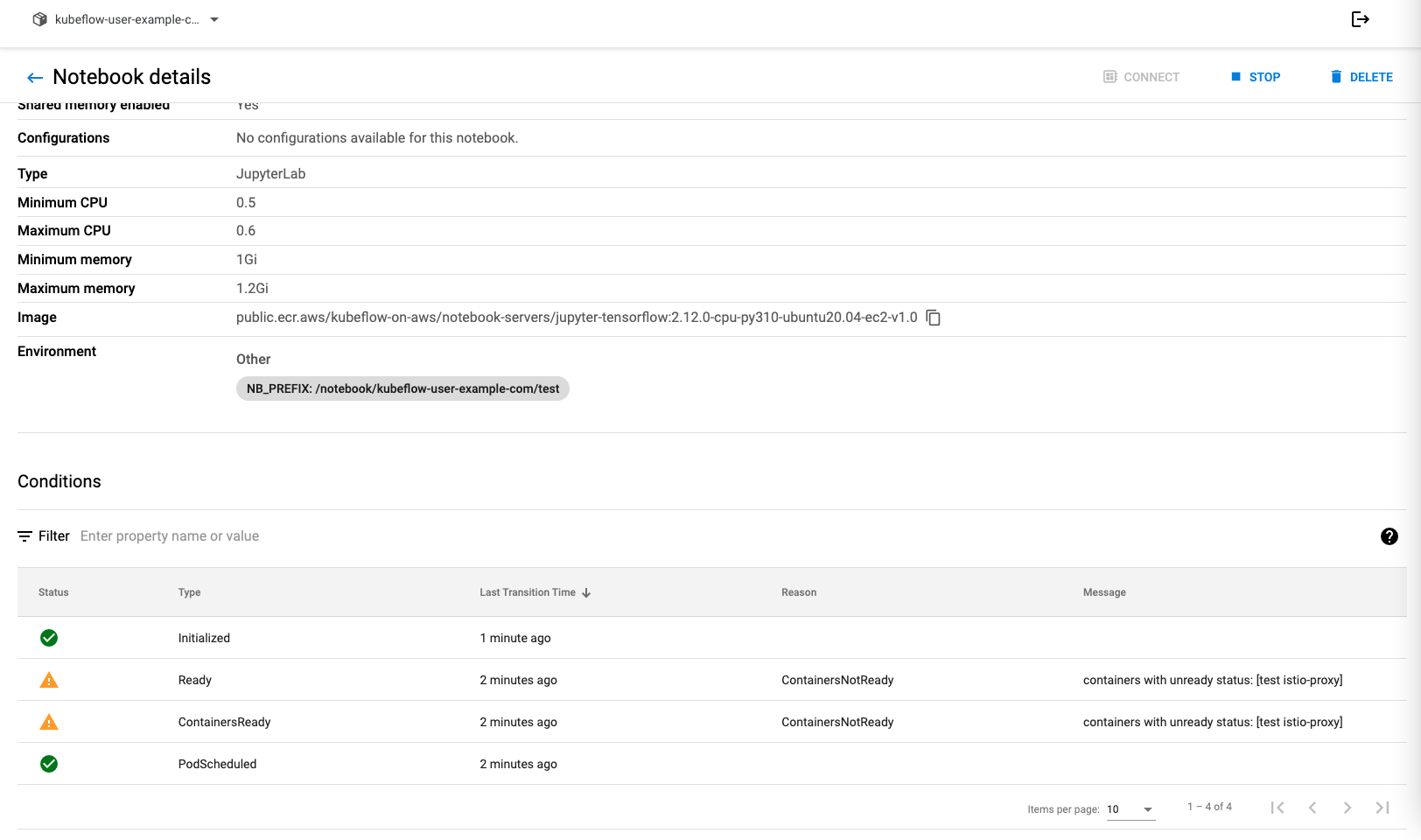
노드 리소스를 확인하면 jupyter notebook 파드의 memory limit 값이 비이상적으로 설정되어 생기는 원인임을 확인할 수 있다.
Allocatedresources:(Totallimitsmaybeover100percent,i.e.,overcommitted.)ResourceRequestsLimits----------------------cpu665m(16%)2600m(66%)memory1184Mi(1%)3167538380800m(5%)ephemeral-storage0(0%)0(0%)hugepages-1Gi0(0%)0(0%)hugepages-2Mi0(0%)0(0%)attachable-volumes-aws-ebs00nvidia.com/gpu11Events:TypeReasonAgeFromMessage-------------------------NormalStarting109skube-proxyNormalRegisteredNode2m44snode-controllerNodeip-192-168-1-190.ap-northeast-2.compute.internalevent:RegisteredNodeip-192-168-1-190.ap-northeast-2.compute.internalinControllerNormalStarting2m3skubeletStartingkubelet.WarningInvalidDiskCapacity2m3skubeletinvalidcapacity0onimagefilesystemNormalNodeHasSufficientMemory2m3s(x3over2m3s)kubeletNodeip-192-168-1-190.ap-northeast-2.compute.internalstatusisnow:NodeHasSufficientMemoryNormalNodeHasNoDiskPressure2m3s(x3over2m3s)kubeletNodeip-192-168-1-190.ap-northeast-2.compute.internalstatusisnow:NodeHasNoDiskPressureNormalNodeHasSufficientPID2m3s(x3over2m3s)kubeletNodeip-192-168-1-190.ap-northeast-2.compute.internalstatusisnow:NodeHasSufficientPIDNormalNodeAllocatableEnforced2m3skubeletUpdatedNodeAllocatablelimitacrosspodsNormalNodeReady107skubeletNodeip-192-168-1-190.ap-northeast-2.compute.internalstatusisnow:NodeReadyNormalUnconsolidatable66skarpenterprovisionerdefaulthasconsolidationdisabled# 모으는 설정 비활성화 WarningEvictionThresholdMet25skubeletAttemptingtoreclaimephemeral-storageNormalNodeHasDiskPressure20skubeletNodeip-192-168-1-190.ap-northeast-2.compute.internalstatusisnow:NodeHasDiskPressure
파드 limit 값을 수정하면 해결되지만,, kubeflow 플랫폼을 사용할 때마다 limit 값을 수정할 수 는 없기에 깃 이슈를 생성해둔 상태이다. 이슈가 해결되면 업데이트하겠다.