Production Kubernetes Online Study (=PKOS)는 쿠버네티스 실무 실습 스터디입니다.
CloudNet@ Gasida(가시다)님이 진행하시며, 책 "24단계 실습으로 정복하는 쿠버네티스"을 기반으로 진행하고 있습니다.
Logging?
애플리케이션 실행 중 발생하는 이벤트, 작업, 오류 등의 정보를 기록하는 프로세스이다. 로깅의 주요 목적은 프로그램의 실행 상태를 추적하고, 문제 발생 시 원인을 찾기고, 내부 감사를 기록하기 위함이다. 로그 파일은 시간 순서대로 저장되며, 대부분의 경우 텍스트 파일 또는 데이터베이스에 저장된다.
쿠버네티스 환경에서도 컨테이너 엔진이나 런타임이 제공하는 기본적인 로깅 기능이 있으나 충분하지 않다. 컨테이너가 크래시되거나, 파드가 축출되거나, 노드가 종료된 경우에도 애플리케이션의 로그에 접근할 수 없기 때문이다.
따라서, 쿠버네티스에서 로그는 노드, 파드 또는 컨테이너와는 독립적으로 별도의 스토리지와 라이프사이클을 가져야 한다. 이 개념을 클러스터-레벨-로깅 이라 하며 이를 위해 별도의 벡엔드 솔루션이 필요하다. 쿠버네티스에 사용할 수 있는 로깅 솔루션은 3가가지 오픈소스 프로젝트를 결합한 PLG 스택(Promtail, Loki, Grafana) 또는 ELK(Elasticsearch, Logstash, Kibana)있다. 이번 블로그 글에서는 PLG 스택을 알아볼 것이며 로깅 시스템인 Loki 와 로그 수집 에이전트인 Promtail 을 설치하하여 클러스터-레벨-로깅을 테스트해보겠다.
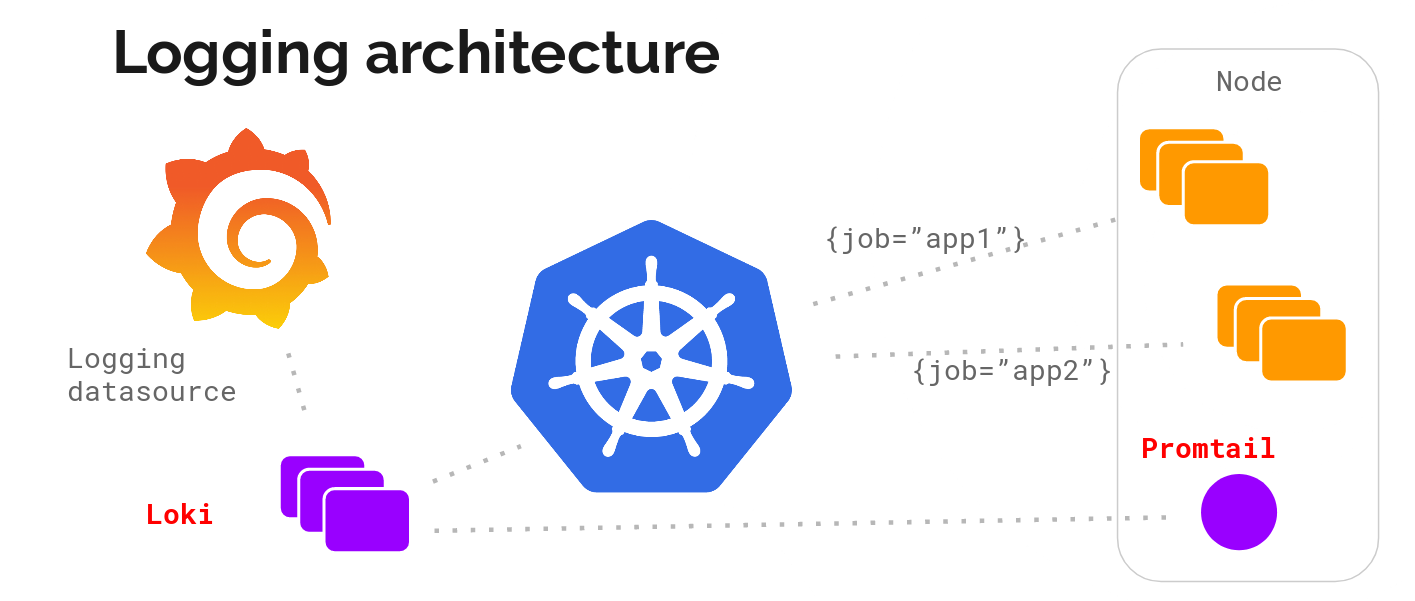
Loki
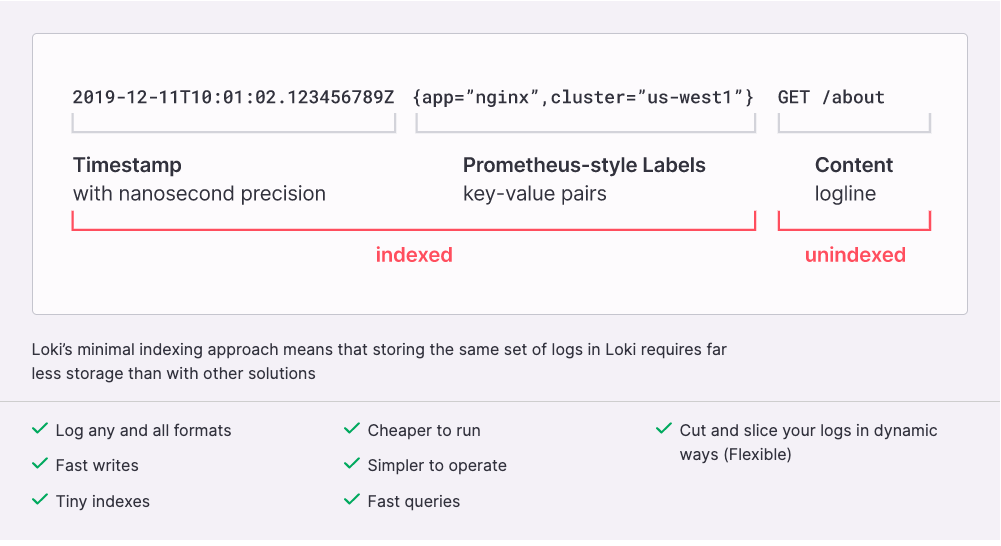
Loki는 Grafana Labs에서 개발한 경량 로깅 시스템으로, 쿠버네티스 환경에서 메타데이터를 기반으로 로그를 수집하고 빠르게 처리할 수 있다. 그리고 Prometheus와 호환되는 레이블 기반 질의 및 필터링 기능을 제공하며, Grafana와 통합을 통해 로깅 데이터를 대시보드에서 확인이 가능하다. 로깅 수집 에이전트인 Promtail을 사용하여 로깅을 수집하며 이를 통해 쿠버네티스 리소스(노드, 파드 또는 컨테이너)와는 독립적으로 별도의 스토리지와 라이프사이클을 가진다.
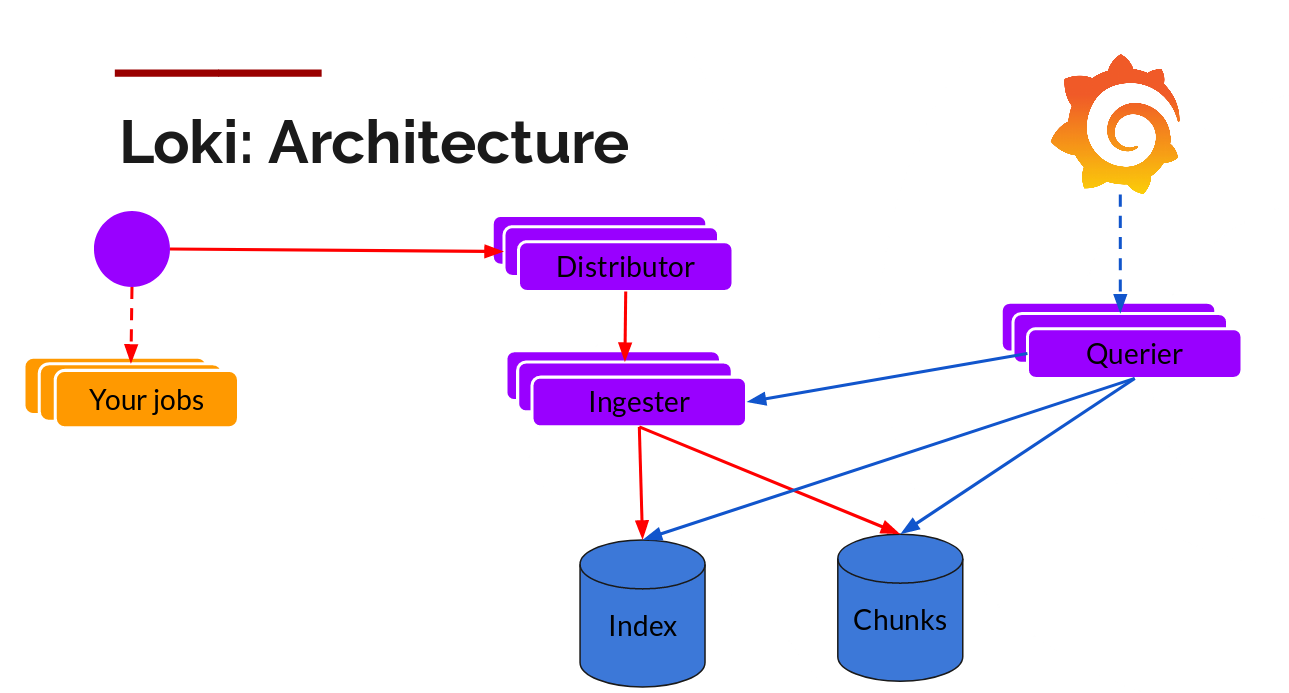
그림에서 화살표 빨강은 로그 Write, 파랑은 Read를 의미한다. 또한, 각 구성 컴포넌트들은 HA를 지원하여 컴포넌트 내부 구성 하나에 장애가 발생하더라도 서비스가 중단되지 않는다.
Your Jobs : 로그 수집 에이전트로 사용자 정의에 맞게 로그를 수집하여 로키 서버(Distributor)에 전달한다. 로그 수집 에이전트로 Promtail를 사용하나 fluent, fluentbit 과 호환이 가능하다.
Distributor(디스트리뷰터): Distributor는 로그 데이터를 수신하고, 해당 데이터를 인제스터(Ingester)에 분산시키는 역할을 한다. 또한, 레이블의 해시 값을 사용하여 데이터를 적절한 인제스터에 전달하며 로드밸런싱을 통해 로그 데이터를 여러 인제스터에 고르게 분산시켜준다.
Ingester(인제스터): Ingester는 Distributor로부터 로그 데이터를 받아서, 로그 스트림을 청크로 나누고 압축한 후 저장시킨다. 인제스터는 메모리 또는 영구 스토리지에 청크를 저장할 수 있으며, 쿼리어(Querier)에게 저장된 청크에 대한 질의 결과를 제공한다. 청크가 일정 시간 또는 크기에 도달하면 인제스터는 이를 영구 스토리지에 저장시킨다.
Querier(쿼리어): Querier는 사용자로부터 질의를 받아 처리한다. 질의를 처리할 때, 쿼리어는 인덱스를 사용하여 관련된 청크를 찾고, 인제스터 및 영구 스토리지에서 해당 청크를 가져와 질의 결과를 반환한다.
level=error ts=2023-04-01T03:18:30.427197283Z caller=flush.go:144 org_id=self-monitoring msg="failed to flush"err="failed to flush chunks: store put chunk: NoCredentialProviders: no valid providers in chain. Deprecated.\n\tFor verbose messaging see aws.Config.CredentialsChainVerboseErrors, num_chunks: 1, labels: {app_kubernetes_io_component=\"read\", app_kubernetes_io_instance=\"loki\", app_kubernetes_io_name=\"loki\", app_kubernetes_io_part_of=\"memberlist\", cluster=\"loki\", container=\"loki\", controller_revision_hash=\"loki-read-7749df4969\", filename=\"/var/log/pods/loki_loki-read-2_a8fab5a2-e78b-4cff-9f8d-ba0ee5952a3c/loki/0.log\", job=\"loki/loki-read\", namespace=\"loki\", pod=\"loki-read-2\", statefulset_kubernetes_io_pod_name=\"loki-read-2\", stream=\"stderr\"}"level=info ts=2023-04-01T03:18:30.427244754Z caller=flush.go:168 msg="flushing stream"user=self-monitoring fp=33d14d11bfd98f55 immediate=falsenum_chunks=1labels="{app_kubernetes_io_component=\"read\", app_kubernetes_io_instance=\"loki\", app_kubernetes_io_name=\"loki\", app_kubernetes_io_part_of=\"memberlist\", cluster=\"loki\", container=\"loki\", controller_revision_hash=\"loki-read-7749df4969\", filename=\"/var/log/pods/loki_loki-read-2_a8fab5a2-e78b-4cff-9f8d-ba0ee5952a3c/loki/0.log\", job=\"loki/loki-read\", namespace=\"loki\", pod=\"loki-read-2\", statefulset_kubernetes_io_pod_name=\"loki-read-2\", stream=\"stderr\"}"
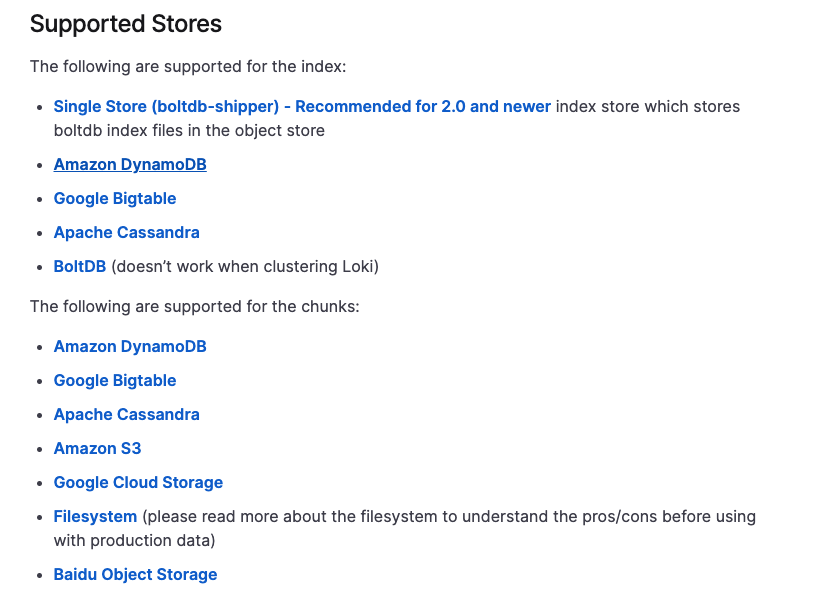
공식문서 예제 storage_config 가 최신 기준으로 업데이트된 것 같지 않다. 필자의 경우 배포 yaml로 구성을 설정하니 정상적으로 작동했다.
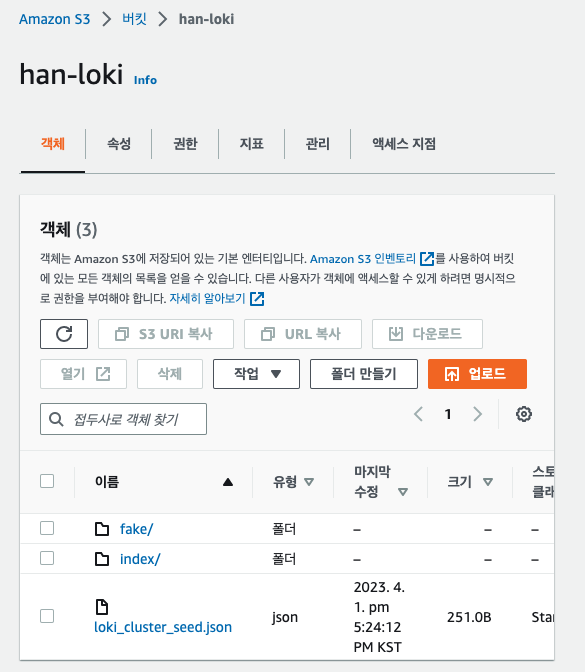
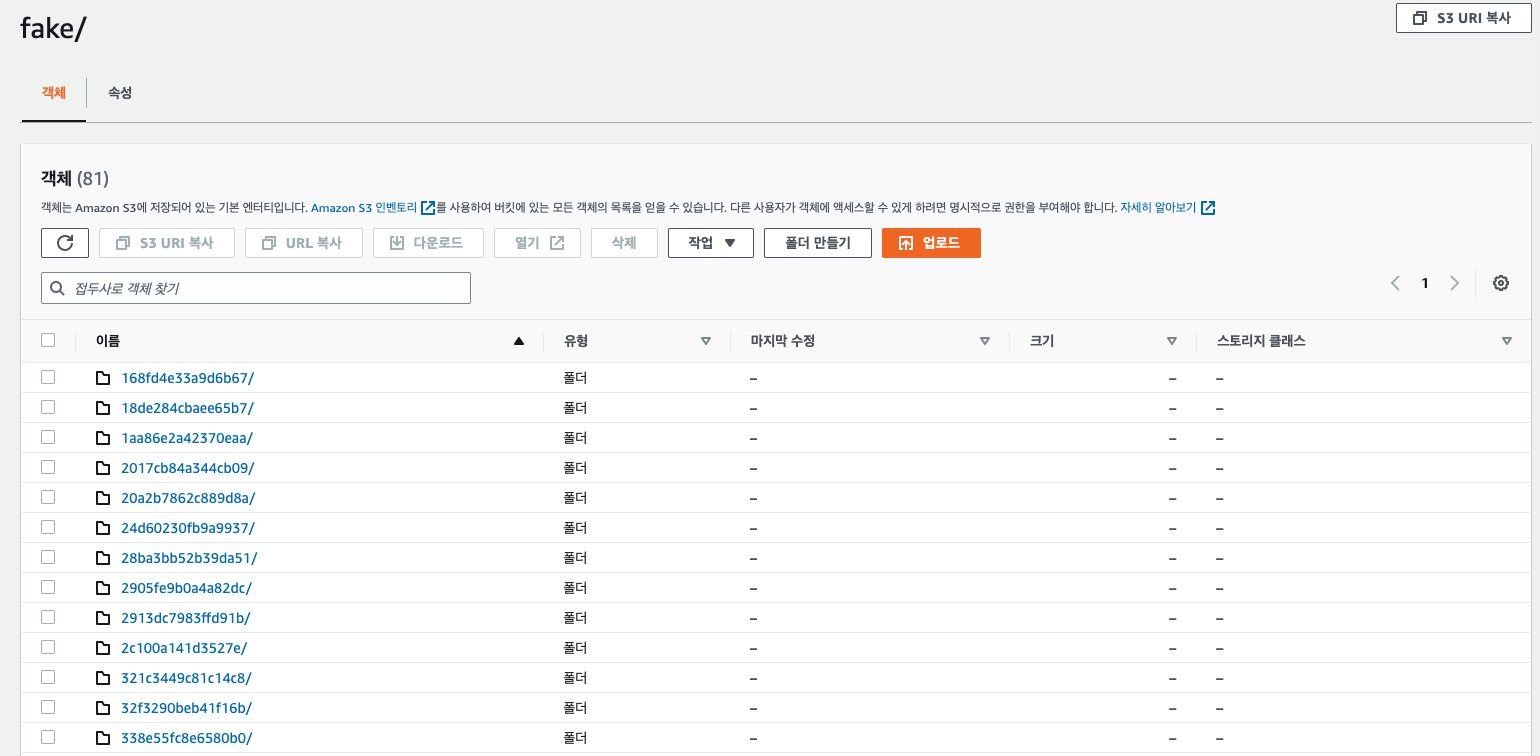
S3 디렉토리에 chunk 폴더가 없다?이슈 에 따르면 멀티테넌트 구성에서 loki를 실행할때 인증이 비활성화하면 기본적으로 fake 폴더에 저장된다고 한다. fake폴더 안에는 정상적으로 chunk가 들어가있는 것을 확인할 수 있으나 다중 클러스터에서 배포시 loki 별로 인증이 필요할 것 같다.
dynamoDB에 인덱스를 저장하고 싶어요.
해결해야할 문제다. 현재 S3에 index값이 들어가는데 dynamodb에 옮겨야 한다. 헬름차트에 table-manager 설정이 두개(table-manager, tableManager)여서 설정이 안 먹힌다. 추가 원인으로는 깃허브 이슈( https://github.com/grafana/loki/issues/5070) 설정값( extraArgs)인데 적용이 안된다. 추후 해결시 업데이트하겠다.
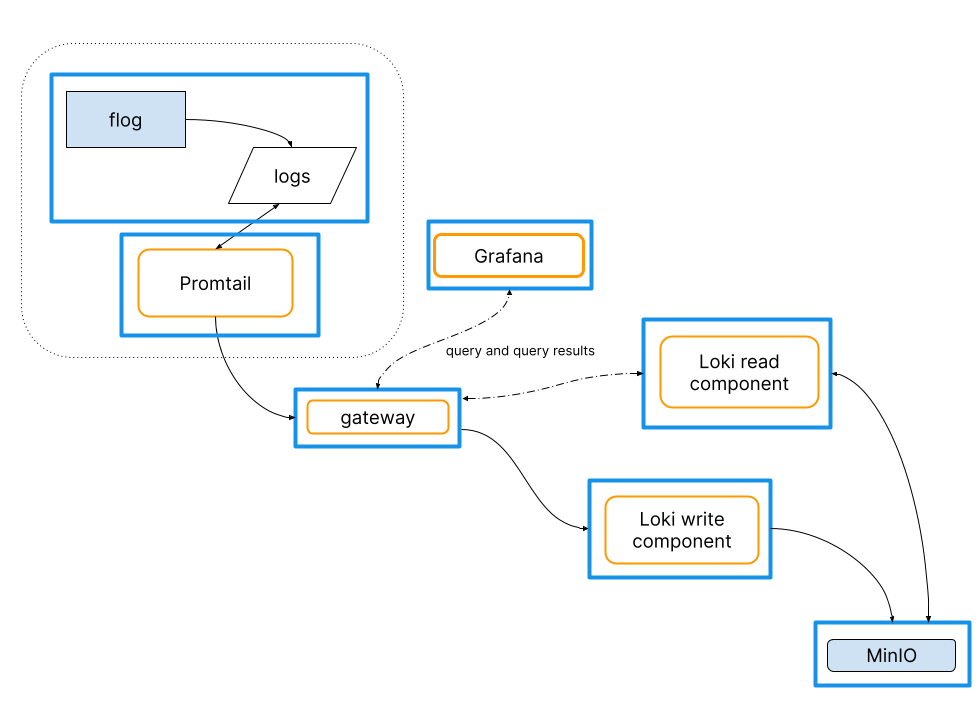
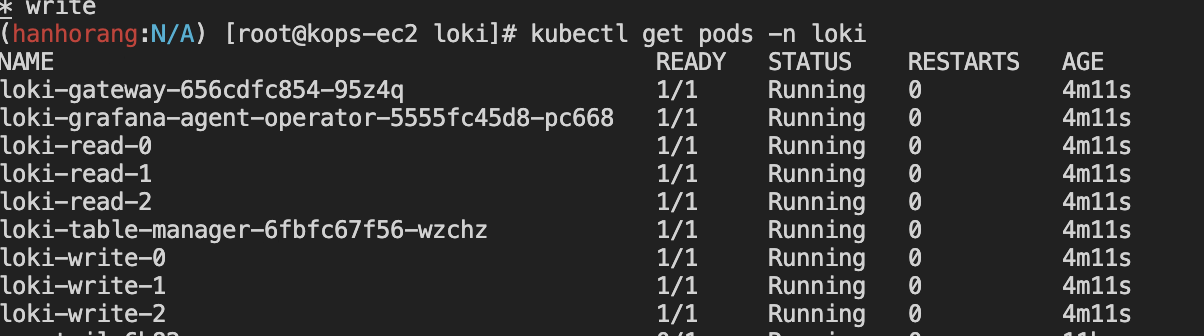
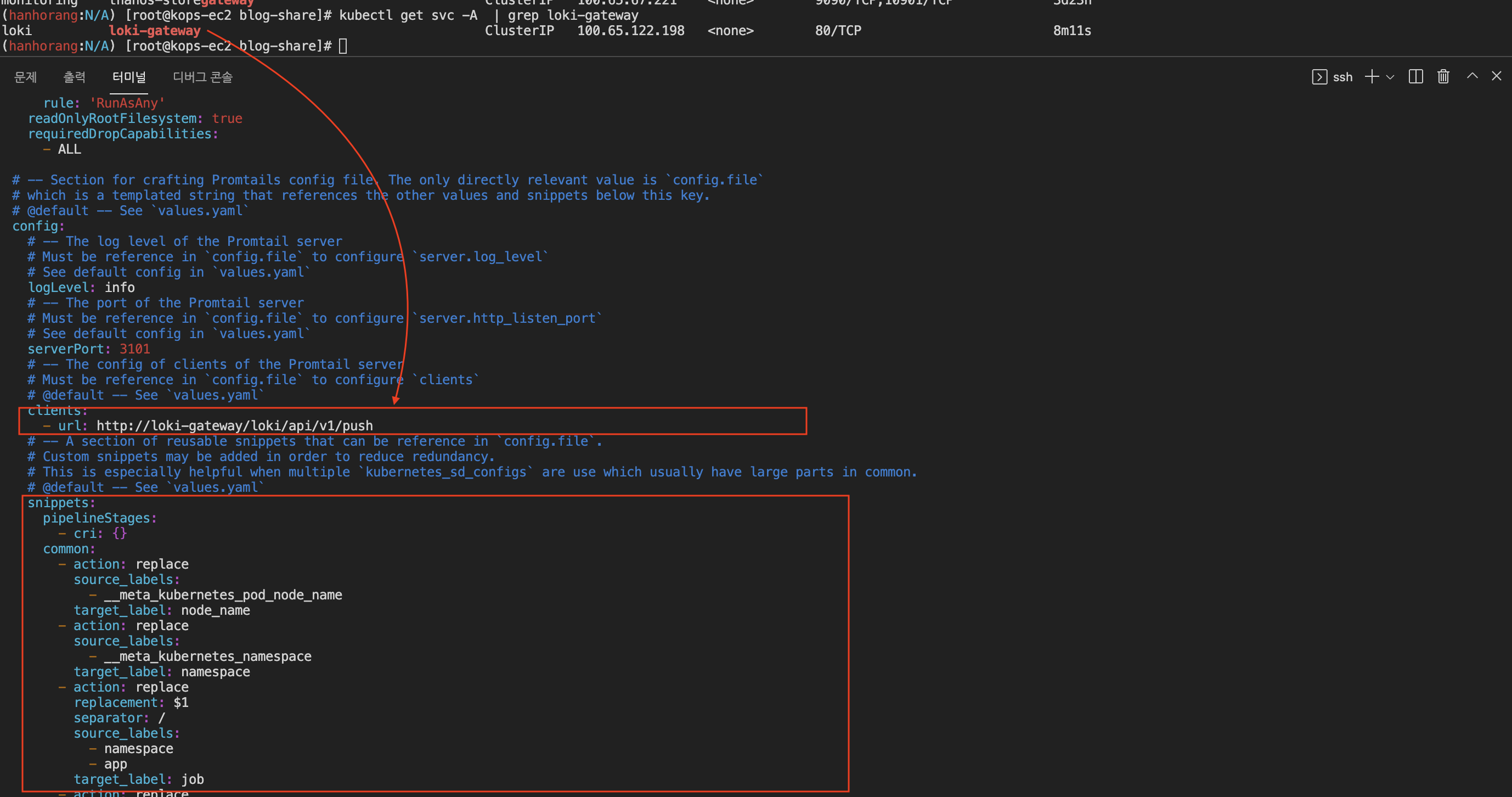
파드 로그는 파드가 올라간 노드 /var/log/pods 에 저장되어 있다. 파드의 로그를 확인하고 그라파나 대시보드에서 로키가 해당 로그를 긁어오는지 확인하자.
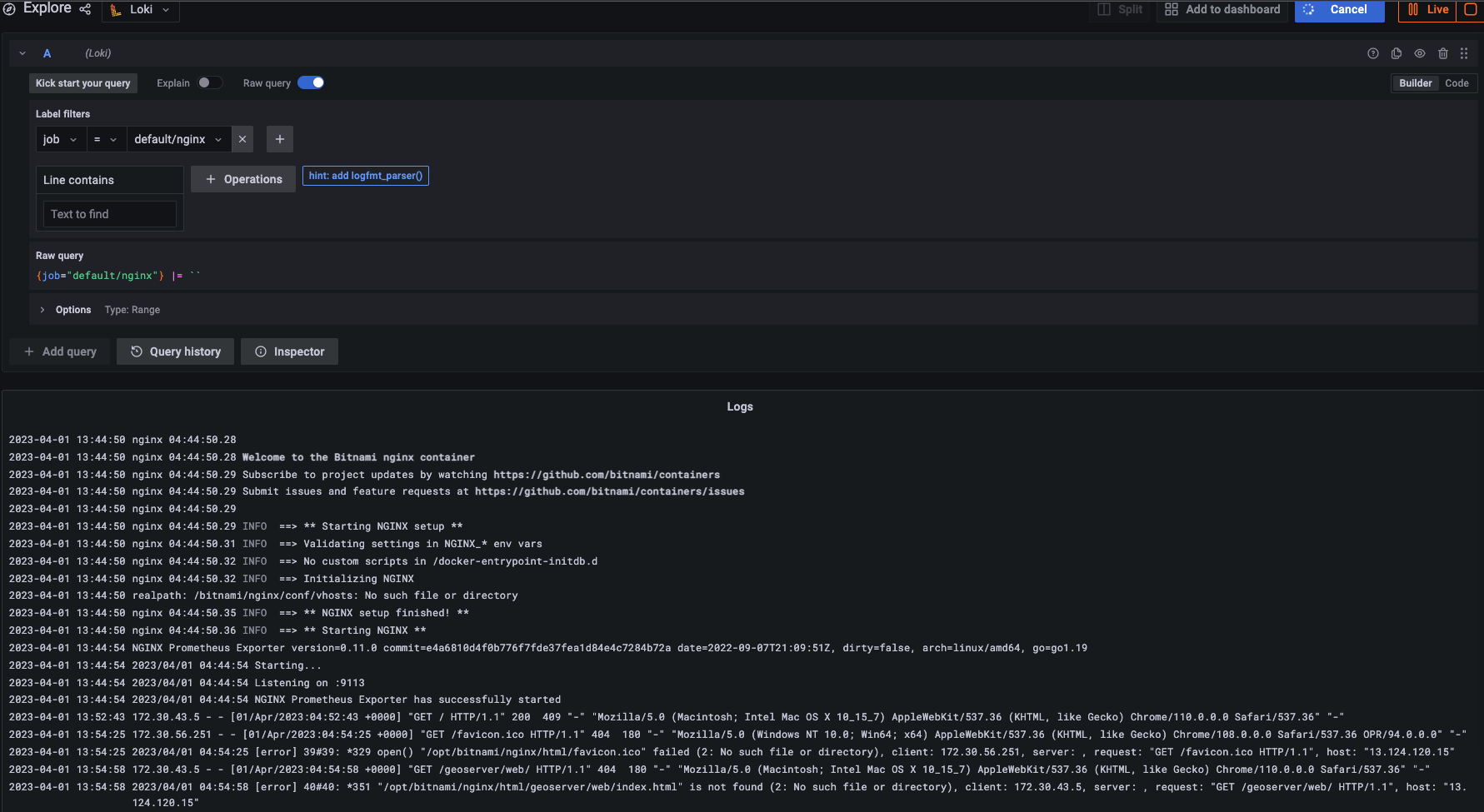
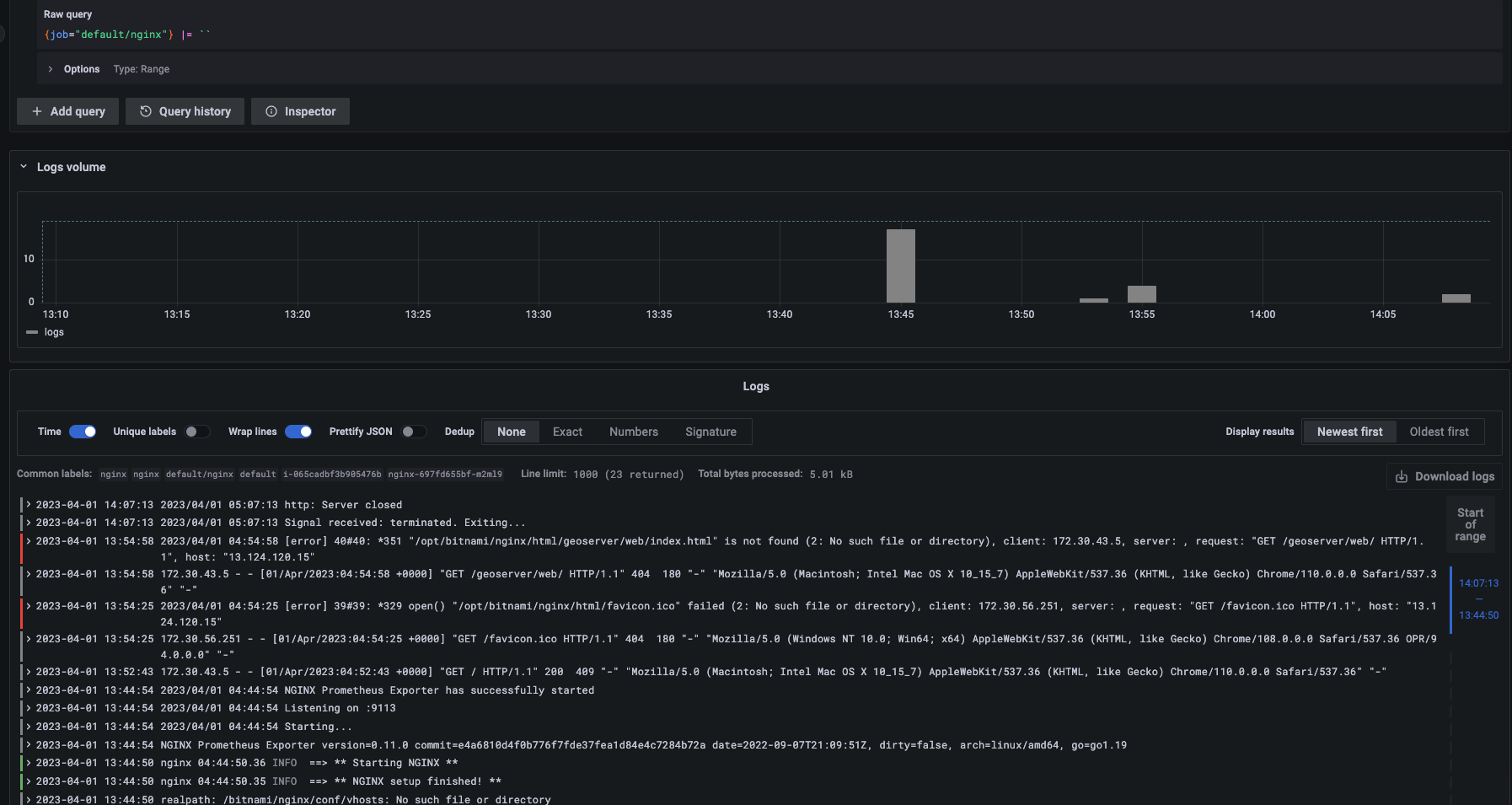
[Explorer] → Job = default/nginx 설정 후 로그 확인
잘 들어온다! 이어서 파드 라이프사이클과 독립적으로 로그가 관리되는 지 확인하겠다. nginx 파드를 삭제하고 파드 로그와 로키를 확인하겠다.
1
helm uninstall nginx
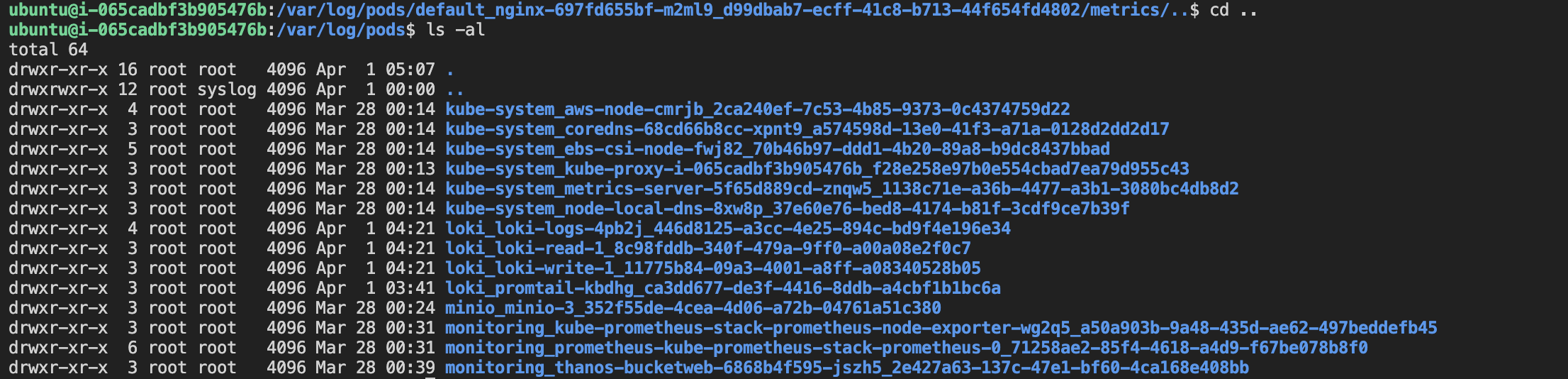
아래 디렉토리를 확인하면 nginx 파드가 삭제되어 로그 디렉토리가 삭제된 것을 확인할 수 있다.
파드가 삭제되었지만 그라파나(로키) 에서 nginx 로그를 확인할 수 있다.
마치며
그라파나 공식 문서를 참고하니 엔터프라이즈에 대한 지원만 활발한 느낌이다. 오픈소스로 설치시 연동 부분과 최신 버전 호환 문제로 테스트하는 데도 오랜 시간이 걸렸다. 특히 인덱스 데이터를 dynamodb 에 연동해야 했지만 설정 문제로 실패했고 S3에 인덱스, 청크 데이터를 저장시켰다. 이 부분은 공식 문서를 최신 버전으로 업데이트를 하거나 예가 나오면 업데이트하겠다.