금일 포스트 글에서는 이벤트 대응 프로세스 과정 중 성능 지연에 관해 다뤄보려 합니다. 서버 자원 중 CPU, 메모리, Disk 측면에서 서버 지연 원인, 지표, 처리 방안을 다뤄볼 예정입니다. 또한, 쿠버네티스(EKS) 환경에서 그라파나 대시보드를 통해 서버 지표를 확인할 예정입니다. 참고는 책 [Devops TroubleShooting] 2장을 참고하였습니다.
CPU, 메모리, Disk
서버 지연을 위한 핵심 지표로 CPU, 메모리, 디스크 개념을 확인하겠습니다. (정리 ChatGPT)
- CPU (Central Processing Unit)
- 컴퓨터의 뇌와 같은 역할을 합니다.
- 모든 계산과 처리를 담당하며, 프로그램의 명령어를 해석하고 실행합니다.
- CPU 단위로는 주파수와 코어가 있습니다. 주파수로는 MHz, GHz 단위로 표시되며 3.0 GHz의 CPU는 1초에 30억 번의 연산을 수행할 수 있습니다. 이와 반면 코어는 여러 작업을 동시에 처러할 수 있는 것을 뜻합니다. 대시보드에서 1.0 같이 정수로 표시되며 하나의 코어를 나타냅니다.
- 메모리 (RAM, Random Access Memory)
- 컴퓨터가 현재 실행 중인 프로그램과 데이터를 임시로 저장하는 공간입니다.
- 전원을 끄면 저장된 정보는 사라집니다.
- 접근 속도가 빠르기 때문에 컴퓨터의 작업 효율성을 높여줍니다.
- RAM 용량은 보통 GB 로 표시됩니다. 속도는 메모리 기술 사양(DDR3, DDR4) 등의 달라지며 주파수에 따라 달라집니다.
- DISK (하드 드라이브 또는 SSD)
- 데이터를 영구적으로 저장하는 장치입니다.
- 전원을 꺼도 저장된 데이터는 유지됩니다.
- 하드 드라이브는 기계적인 구동 방식을 가지며, SSD는 반도체를 사용하여 더 빠른 접근 속도를 제공합니다.
- DISK 용량은 주로 GB, TB단위로 표시됩니다. HDD(하드디스크는) RPM(회전속도)로 속도를 나타내며 5400RPM, 7200RPM 로 표시되며, SSD 는 읽기/쓰기 속도를 MB/s 단위로 나타냅니다.
이 핵심 지표들은 서로 유기적으로 운영됩니다.
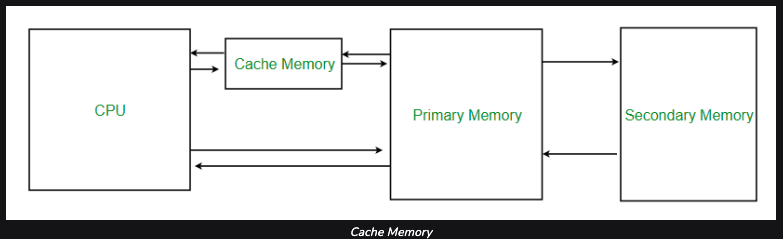
https://www.geeksforgeeks.org/cache-memory-in-computer-organization/
- Chche Memory 는 CPU 내부에 위치하며 매우 빠른 속도의 소량의 메모리입니다. 그 목적은 CPU가 데이터에 더 빠르게 접근하도록 돕는 메모리입니다.
- Primay Memory 는 RAM, Seconadry Memory 는 DISK 입니다.
컴퓨팅 운영 시나리오 보자면 다음과 같습니다.
- DISK에 모든 데이터와 프로그램이 저장됩니다.
- 컴퓨터가 프로그램을 실행하거나 파일을 열 때, 해당 데이터는 빠르게 접근할 수 있는 메모리(RAM)로 이동합니다.
- CPU는 메모리에 저장된 데이터를 바로 처리합니다. 처리된 결과는 필요에 따라 다시 DISK에 저장될 수 있습니다.
지연이 일어나면 어떻게 될까?
서버 운영 중 지연이 일어난다면 무엇을 확인해야 할까요? 세부 포지션마다 지연 원인을 찾는 방법이 다를 것 입니다. 참고 서적에서는 포지션별로 지연 원인을 찾는 행동에 대해 분석하여 정리하였습니다.
- 개발자라면 최근에 체크인한 코드가 예전보다 훨씬 느리게 실행되는지 추적
- 품질보증 엔지니어라면 운영환경으로 이관되기 전 부하 테스트 수행
- 시스템 관리자는 지표 확인 후 더 많은 시스템 자원 구입
많이 공감이 되는 내용입니다. 보통의 경우 지연이 발생한다면 git 히스토리와 알람이 설정된 지표를 확인하겠죠? 이 중에서 지표를 세부적으로 확인해보겠습니다.
서버 지표 확인
리눅스 서버에서 명령어를 통해 지표를 확인해보겠습니다. 해당 명령어와 내용은 참고 책을 확인하였습니다.
CPU 지표
|
|
일반적으로 1분, 5분, 15분 동안의 평균 부하를 나타냅니다.
0.12: 지난 1분 동안의 평균 부하0.15: 지난 5분 동안의 평균 부하0.09: 지난 15분 동안의 평균 부하
평균 부하는 시스템의 전반적인 부하를 나타내며, CPU, 디스크 I/O, 네트워크 I/O 등 여러 요소가 포함됩니다. 즉, 평균 부하는 시스템에 대기 중인 작업의 평균 수를 나타내는 지표입니다.
메모리 지표
|
|
- 높은 프로세스 제거를 원할시
k를 누르고 PID 입력, 메모리 정렬은 M 키를 입력하면 됩니다. - Mem은 RAM, Swap은 파일 캐시량을 뜻합니다. 사용 가능한 메모리가 26768k 가 없기때문에 고갈된 것으로 모이나 리눅스 파일 캐시를 생각해야합니다. 파일에서 RAM으로 불러오고 실행을 완료했다하더라고 제거하지 않습니다. 정확한 판단을 위해 997408k의 RAM 사용량과 286040 리눅스 파일 캐시로 사용된 것을 확인해야 합니다. 실제로는 711368(RAM 사용량-리눅스 파일캐시) 의 RAM이 사용된 것 입니다.
- RAM이 고갈되면 OOM Killer 발생하여 다른 프로세스 종료시킬 수 있습니다. 이 경우, /var/log/sys/log에서 out of memory: killed process 로 로그가 찍혀야 합니다.
DISK IO 지표
|
|
여기서 파티션 별로 구분하여 파악, 읽기 쓰기 작업 확인해야 합니다. 또한, 디스크별 정렬도 가능합니다.
|
|
리눅스 서버 지표 기록은 어떻게 해야하나?
sysstat 패키지로 기록이 가능합니다. 패키지 설치시 /etc/default/sysstat 파일을 편집해서 ENABLE=’False’ 를 ‘true’ 로 변경하면 되며, 변경 기록은 /var/log/sysstat 이나 /var/log/sa 에 기록됩니다.
기록된 정보는 $ sar 로 확인 가능합니다.
|
|
각 리소스가 고갈된다면 ?
CPU, 메모리, DIsk 의 리소스가 고갈된다면 시스템에서 발생하는 현상은 다음과 같습니다.
- CPU 고갈 : 시스템 응답 시간이 느려지며, 프로세스가 대기 상태로 전환되어 작업처리가 지연됩니다.
- 메모리 고갈 : 메모리 부족으로 프로세스가 강제 종료된다(OOM Killer), 스왑 영역이 사용되면서 시스템 성능이 저하 됩니다.
- 디스크 고갈 : 새로운 파일 생성할 수 없으며 시스템에 따라 파드가 종료(eviction)될 수 있습니다.
고갈되었을 때의 대응 방안으로는 기존의 불필요할 리소스를 삭제하거나, 새로운 리소스를 추가 증량하면 됩니다.
쿠버네티스에서 지표 확인
쿠버네티스에서는 리눅스 서버의 지표와는 비슷하면서도 다릅니다. 쿠버네티스에서는 서버가 노드로 표시되며 각 애플리케이션은 각 파드에 할당되기 때문입니다. 애플리케이션이 서버가 아닌 파드로 운영되기에 쿠버네피스 관련 지표확인이 필요합니다. 쿠버네티스에서는 각 서버에 지표 확인을 위한 컴포넌트를 배포하는데요. 주요 컴포넌트를 통해 지표를 다양하게 확인할 수 있습니다. 노드 운영체제가 윈도우인 경우에는 windows exporter, NVIDIA GPU 지표인 경우 prometheus-dcgm 확인을 추천드립니다. 이번 글에서는 대표 컴포넌트인 node-exporter 와 kube-state-metrics을 확인하겠습니다.
1. Prometheus-node-exporter
시스템 메트릭을 수집하는 역할을 하는 소프트웨어입니다. Prometheus 모니터링 플랫폼의 일부로서 동작하며 노드에서 시스템 지표를 추출하고 Prometheus 서버가 쉽게 수집할 수 있는 형태로 제공합니다. node-exporter는 collector를 통해 지표를 수집합니다. 이를 통해 확인할 수 있는 지표는 다양합니다.
시스템 외부 상태, 계층별 네트워크, CPU, 메모리, 디스크, 파일시스템, OS 지표등을 확인할 수 있습니다.또한, 시스템 커널 파라미터 지표(perf, sysctl) 도 제공됩니다. 이를 통해 시스템 및 애플리케이션 성능을 분석하는데 사용되지만 추가 작업이 필요합니다. 각 분야별로 세부 지표(가상 메모리 사용, ZFS, XFS 등..) 가 다양하게 제공됩니다. 자세한 내용은 공식 문서를 참고해주세요.
수집된 지표들은 프로메테우스를 통해 확인할 수 있습니다.
|
|
2. kube-state-metrics
쿠버네티스 클러스터 내 오브젝트 상태에 대한 메트릭을 생성하는 컴포넌트입니다. 프로메테우스와 같은 모니터링 시스템에서 사용하기 위한 메트릭을 제공합니다. 쿠버네티스 오브젝트 단위(node, pod, service, deployment 등..) 정말 다양한데요. 이를 통해 쿠버네티스 클러스터의 상태, 성능 및 운영 효율성을 관리하고 최적화하는데 사용됩니다.
대시보드를 통한 지표 확인
위에서 확인한 컴포넌트의 지표들은 kube-prometheus-stack를 통해 손쉽게 가능합니다. EKS에서 kube-prometheus-stack을 배포하고 대시보드인 grafana을 통해 지표를 확인하겠습니다.
|
|
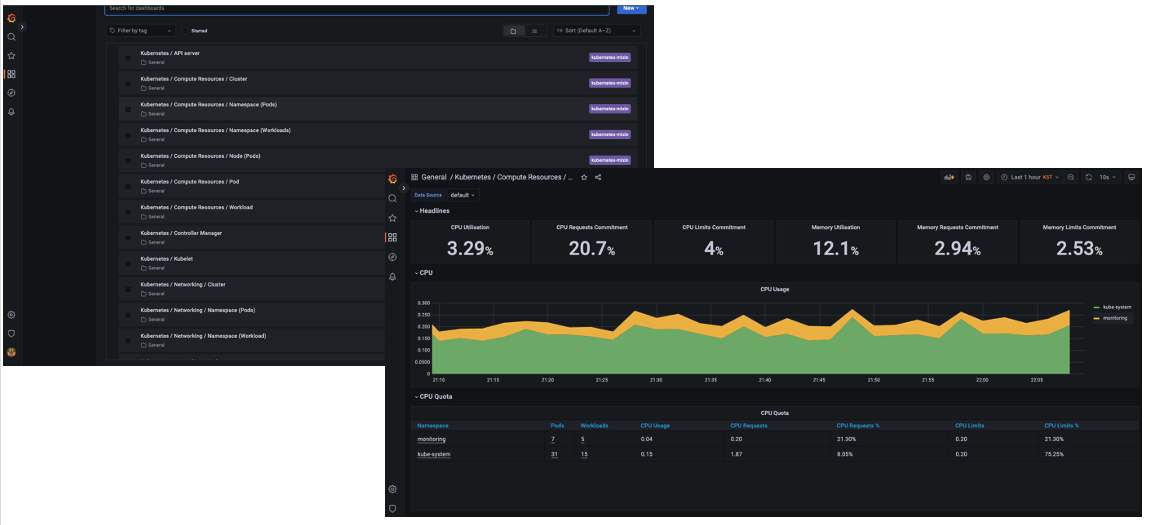
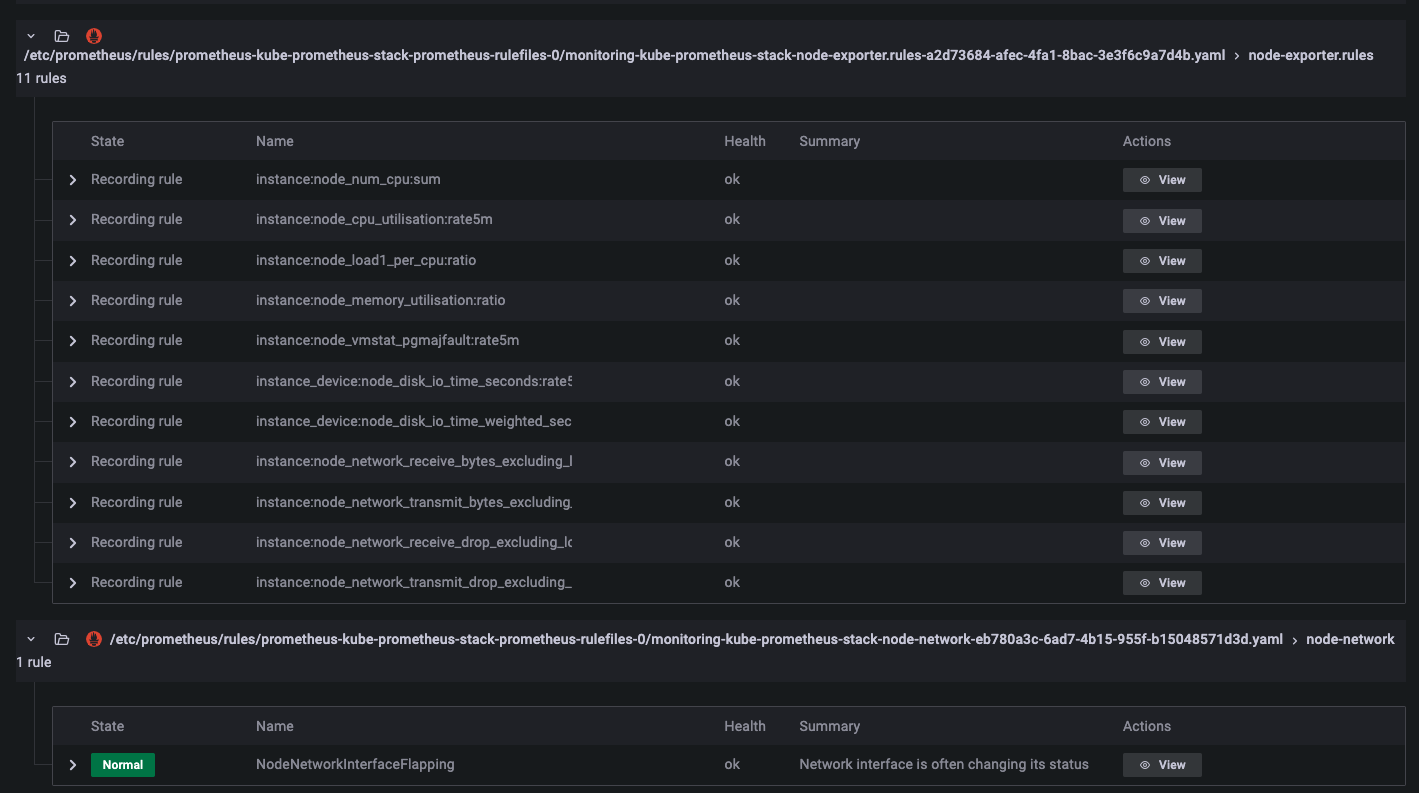
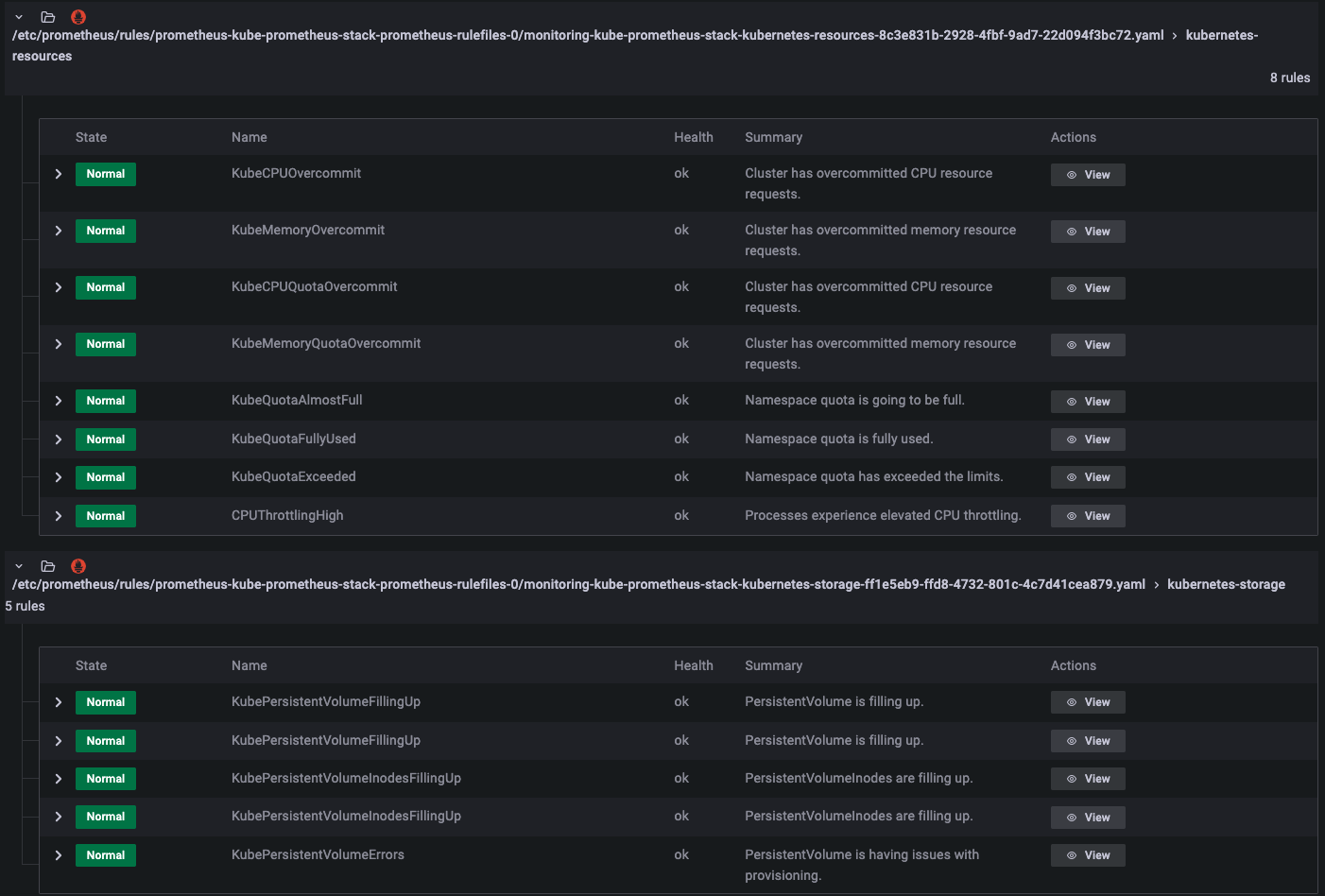
대시보드를 확인하면 해당 컴포넌트를 통해 시각화된 대시보드를 확인할 수 있습니다. 다만, 확인해야할 대시보드와 지표가 너무 많은데요. 어떤 것을 알람을 해야할지 어떤 지표를 확인해야할 지 감이 안오실 것입니다. 이 부분은 기본 알람을 통해 일부 해소를 할 수 있는데요. kube-prometheus-stack 의 default alram을 확인하면 219개의 룰이 설정되어 있습니다. 룰 안에는 쿠버네티스 컴포넌트 별로의 설정 알람과 리소스 알람, 쿠버네티스 오브젝트별 알람을 확인할 수 있습니다.
-
node-exporter 와 kube-state-metrics 알람
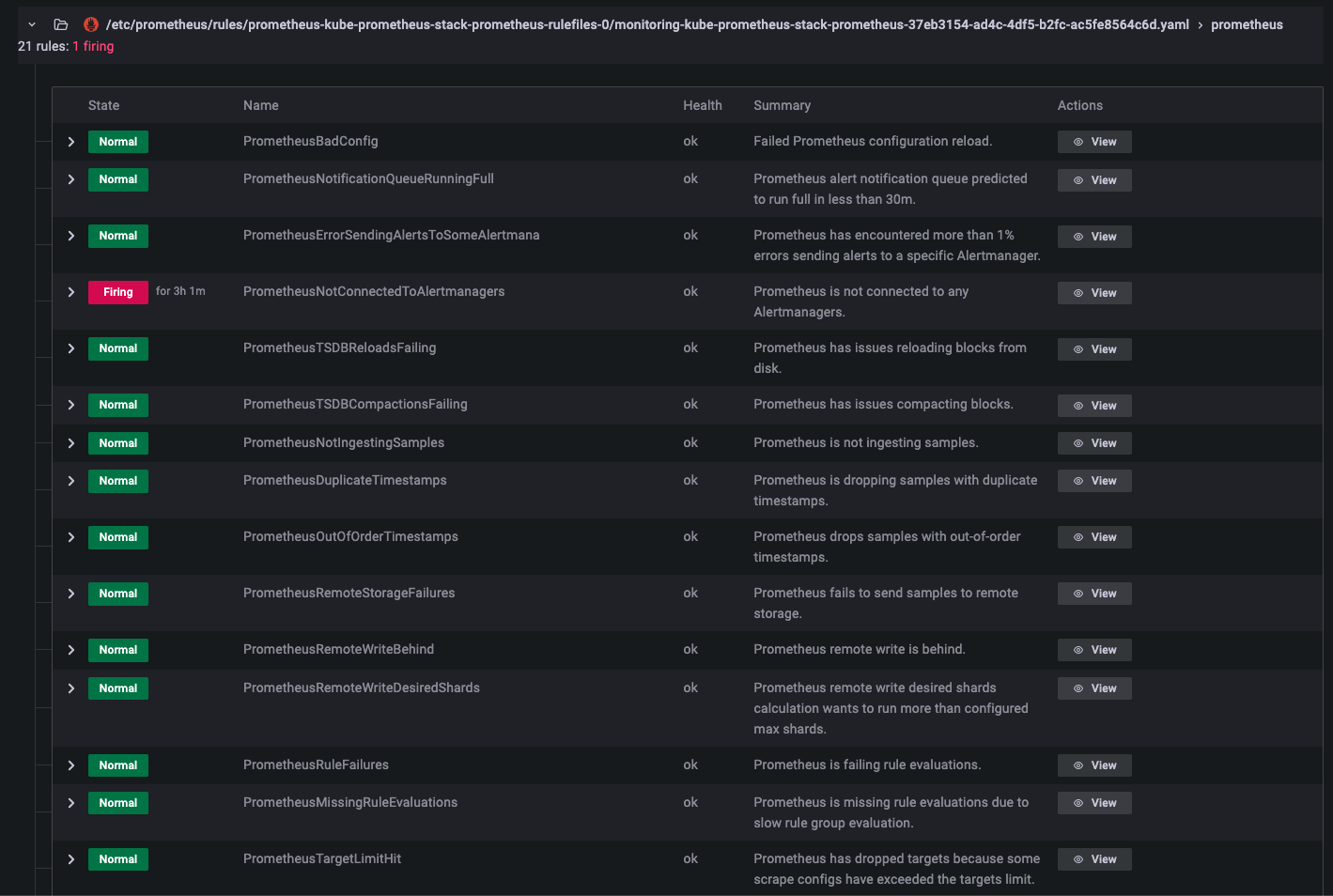
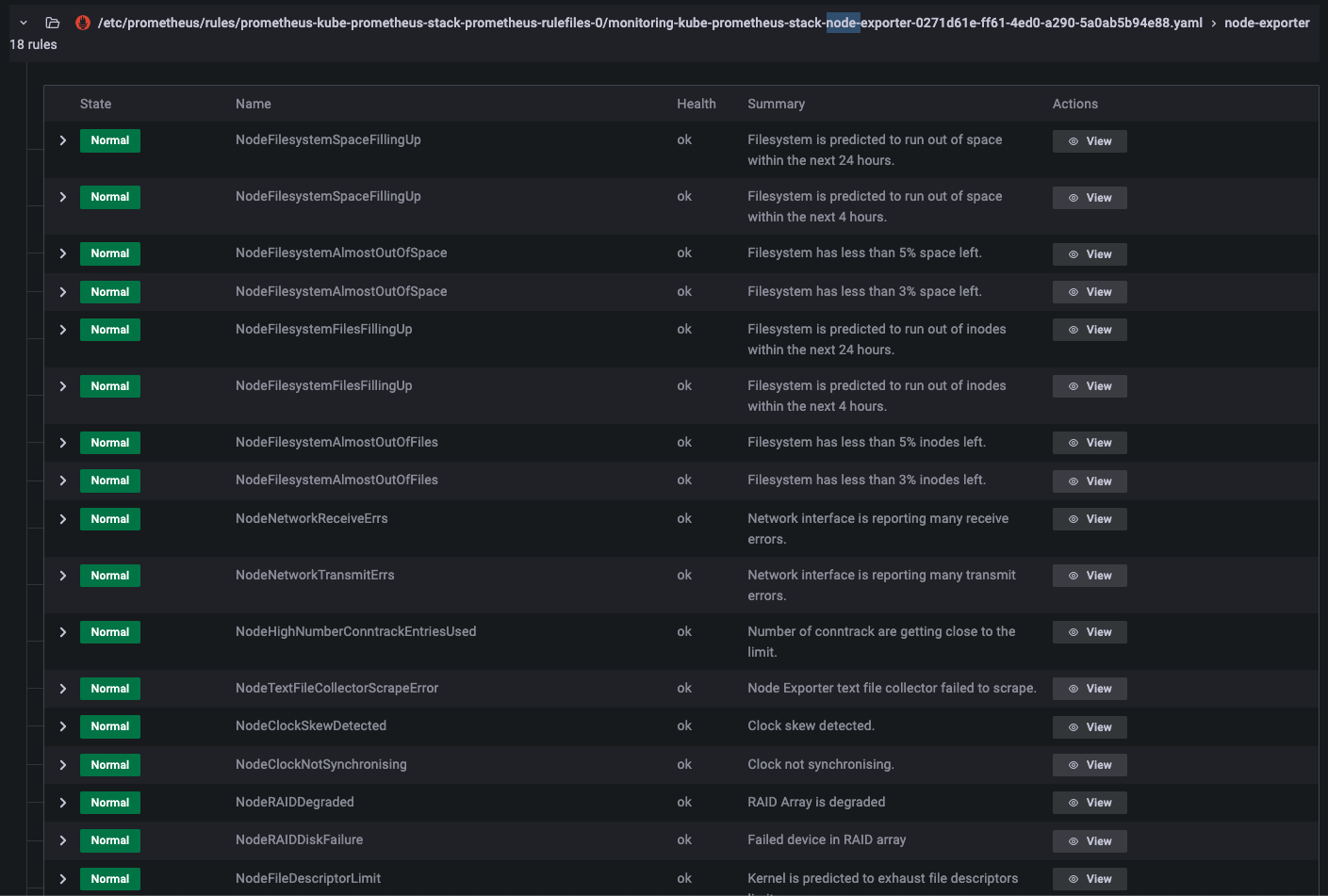
-
리소스 알람
마치며
서버 지연을 확인하기 위해 지표를 시스템별로 확인하였습니다. 트러블슈팅 과정에서 지표 확인은 시작 단계입니다. 한마디로 지표만 확인하고 끝이 아니라 지표를 시작으로 원인 분석을 들어가야 합니다. 예를 들어 지표 확인 후 이슈 있는 애플리케이션의 로그 확인하거나 트레이싱을 확인해야 합니다.