|
|
EKS workshop 아키텍처 이해와 트레이싱 기능 확인하기
스터디에서 관측시스템 관련 좋은 워크샵 링크를 공유해주셨다. 이번 시간에는 해당 워크샵 자료를 토대로 실습 아키텍처 이해와 워크샵 기능 중 트레이싱을 살펴볼 예정이다.
EKS One Observability Workshop 워크샵 링크 : https://catalog.workshops.aws/observability/en-US
관측시스템 아키텍처
워크샵에서 제공하는 아키텍처가 AWS 기반의 실 애플리케이션을 운영하는 예제로 좋은 것 같아 정리한다. 애플리케이션은 애완동물 입양 안내 사이트로 애완동물에 대한 검색 기능과 및 입양 여부에 따라 조회가 달라지는 기능을 제공한다.
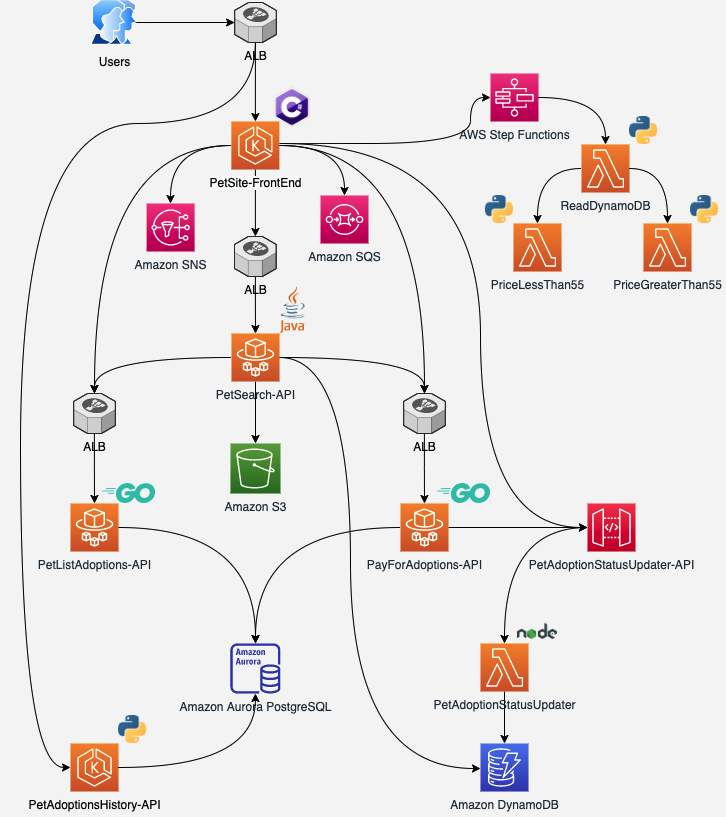
아키텍처 구성 이해
각 모듈은 AWS 서비스로 구성되어 있으며 아키텍처는 다음 아키텍처와 같다. 아키텍처가 많이 복잡하다.. 이해를 위해 아키텍처에서 AWS 서비스 구성 이유와 어떻게 서비스들이 연동하고 있는 지 정리하여 공유한다.
-
각 API 서비스 앞 ALB(Application Load Balancer)를 배치한 이유?
-
로드 밸런싱 : 서버 부하를 줄이고, 높은 가용성과 신뢰성을 제공하여 규모에 따라 자동으로 스케일링되도록 구성
-
컨테이너화 된 워크로드 지원 : ALB는 ECS 및 EKS와 같은 컨테이너화된 워크로드를 지원한다.
-
내구성 및 보안 : ALB은 각 가용 영역에서 실행되어 높은 내구성을 제공하며, AWS WAF, Shield, ACM 같은 보안 서비스와 통합하여 보안을 강화할 수 있다.
-
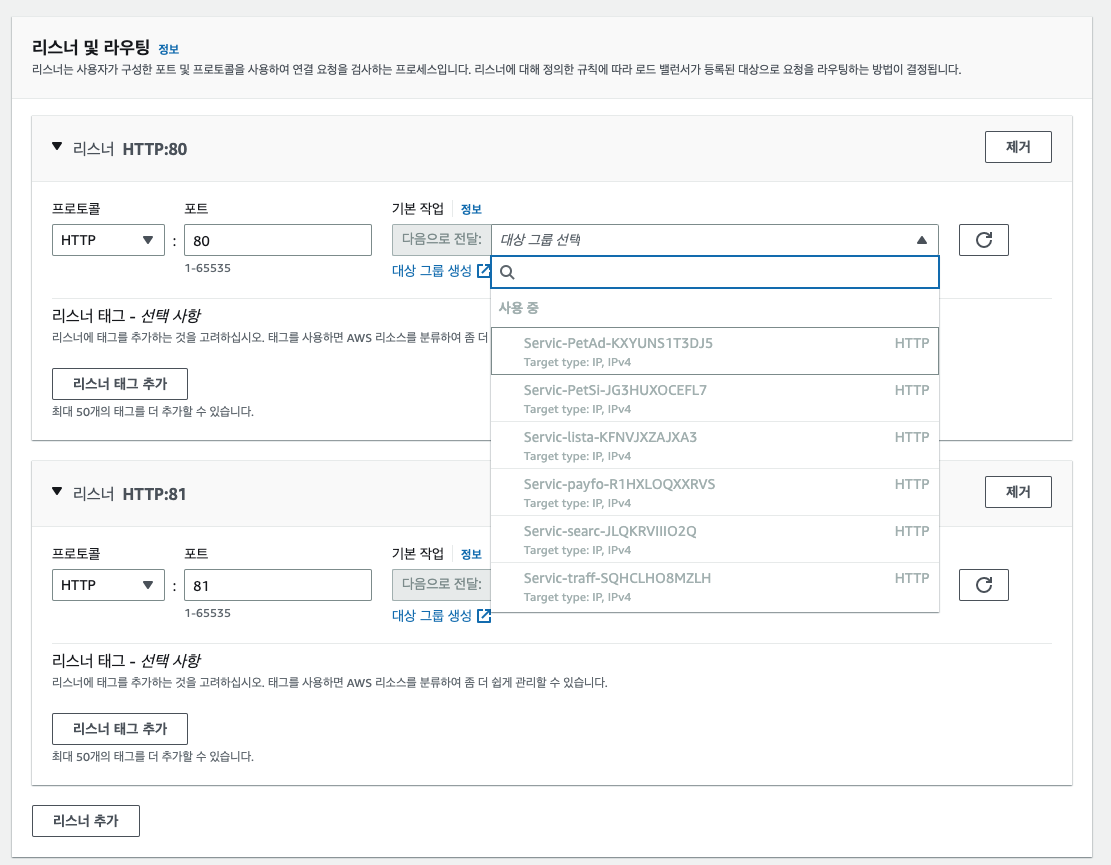
ALB 연동은 AWS 콘솔에서 손 쉽게 가능하다. [EC2] → [대상 그룹] 생성 후, 로드밸런서에서 ALB 생성을 진행하면 연동이 완료된다.
-
-
PetSite-FrontEnd 에 SQS, SNS, StepFunctions를 연결한 이유 ?
-
SNS 연결 이유 ? SNS (Simple Notification Service)는 웹서비스를 통해 모든 인프라 및 앱에 분산 메시징을 제공하는 완전관리형 퍼블리시/서브스크라이브 메시징 서비스이다. 예제에서는 프론트앤드 트래픽 및 상태 값에 알람을 걸고 등록된 이메일에 알람을 보내도록 구성되어 있다.
-
StepFunction 연결 이유 ? StepFunction 은 람다 함수 서비스를 통합하여 워크로드를 구성할 수 있는 서비스이다. 본 예제에서는 호출 테스트를 목적으로 일정 시간마다 dynamodb 에 저장된 애완동물 값을 읽어 애플리케이션 상태를 확인하도록 구성되어 있다. AWS 콘솔에서는 다음과 같이 구성 및 호출 결과를 확인할 수 있다.
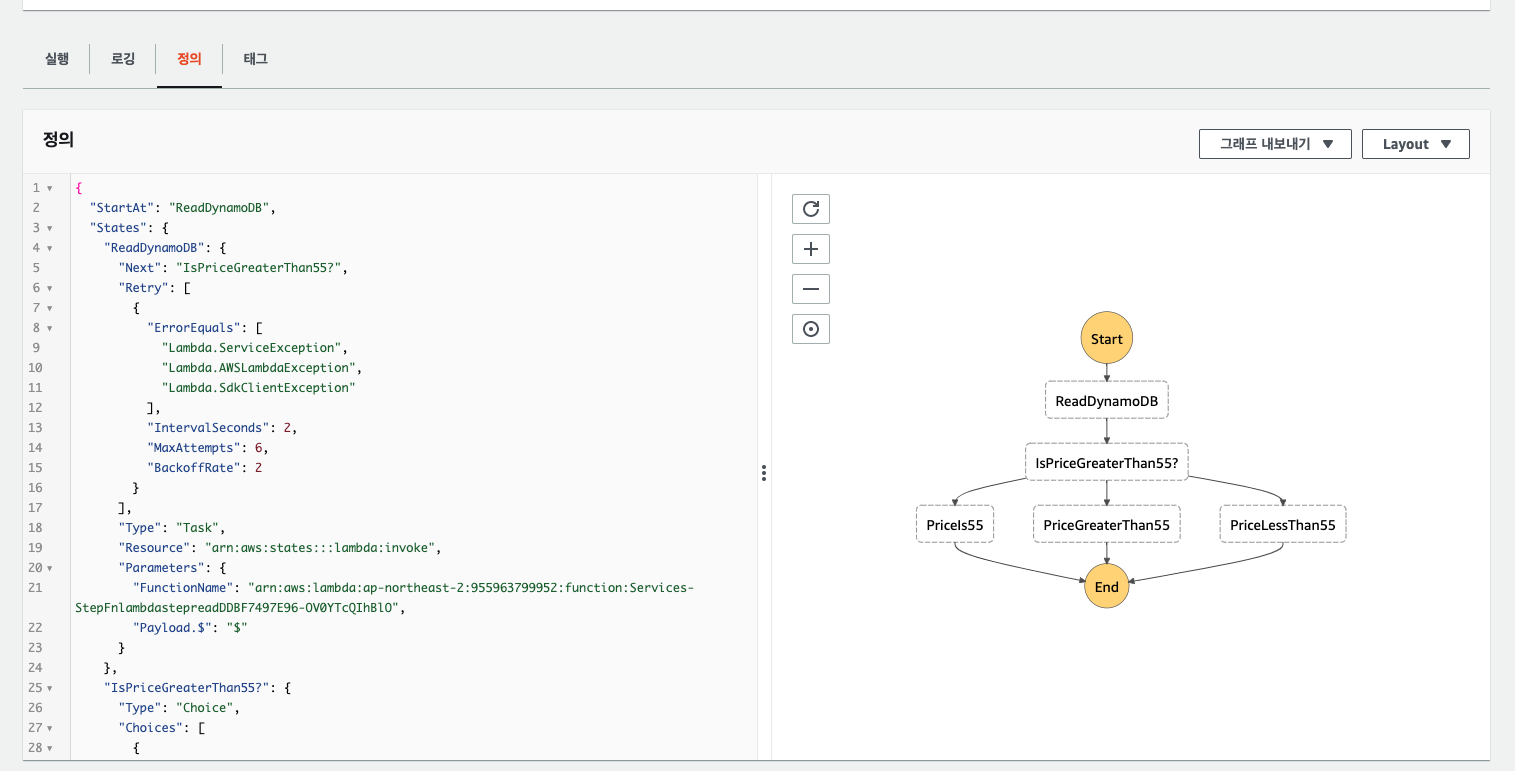
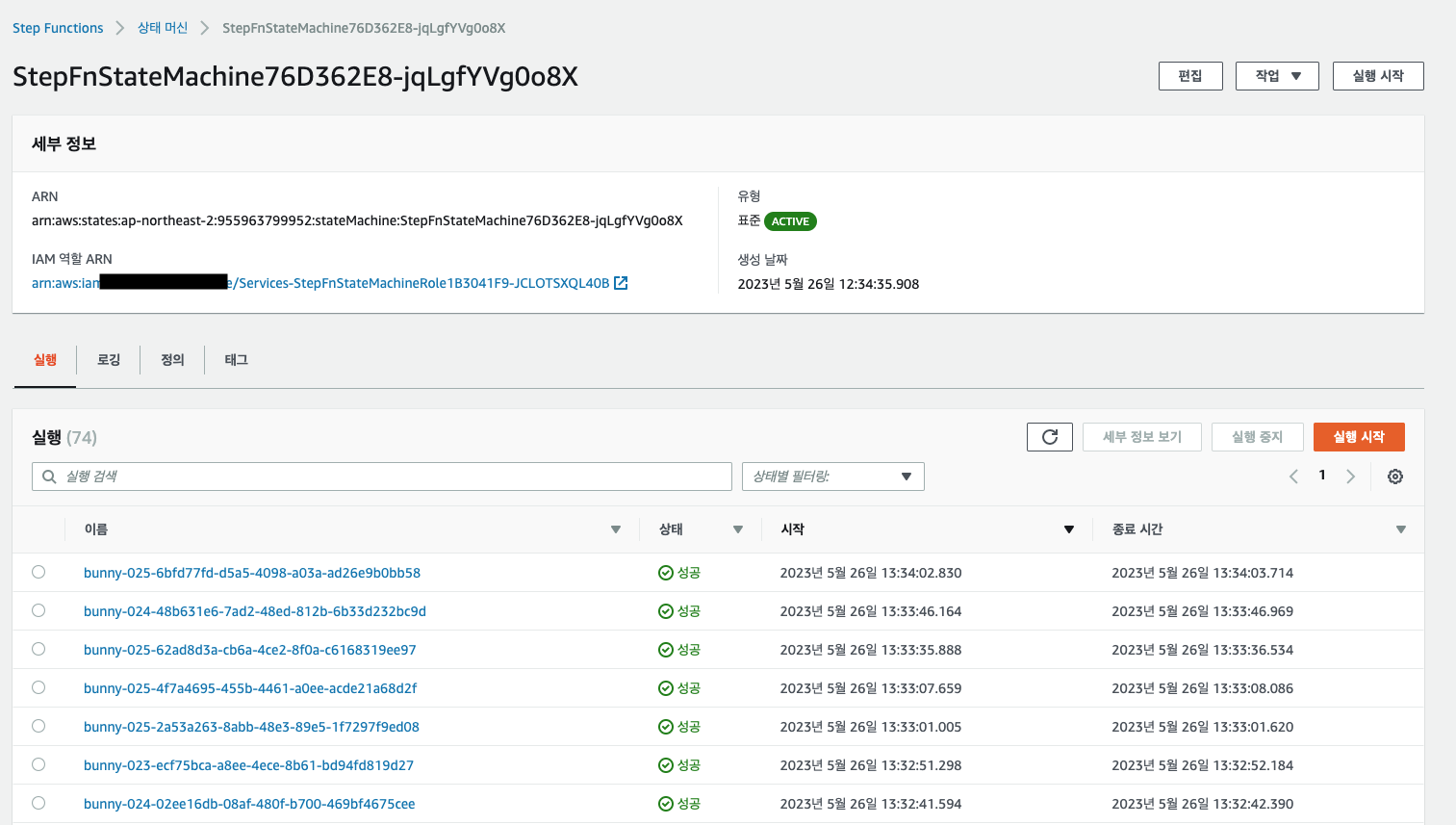
각 람다 함수는 python 으로 구성되어 있으며 코드 이해를 돕기 위해 공유한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26# ReadDynamoDB # DynamoDB 에 저장된 애완동물의 가격을 불러온다. import json import boto3 from boto3.dynamodb.conditions import Key ssm = boto3.client('ssm') dynamodb = boto3.resource('dynamodb') def lambda_handler(event, context): dynamodb_tablename = ssm.get_parameter(Name='/petstore/dynamodbtablename', WithDecryption=False) table = dynamodb.Table(dynamodb_tablename['Parameter']['Value']) response = table.query( KeyConditionExpression=Key('petid').eq(event['petid']) & Key('pettype').eq(event['pettype']) ) response['Items'][0]['price'] = int(response['Items'][0]['price']) return { 'statusCode': 200, 'body': response['Items'][0] }1 2 3 4 5 6 7 8 9 10 11 12# PriceGreaterthan55 # 55 이상의 애완동물을 확인하고 200을 결과 값으로 반환한다. import json def lambda_handler(event, context): # TODO implement print(event) print('ProcessLessthan55 - Execution complete') return { 'statusCode': 200, 'body': json.dumps('ProcessLessthan55 - Execution complete') }1 2 3 4 5 6 7 8 9 10 11 12 13# Pricelessthan55 # 55 미만의 애완동물을 확인하고 200을 결과 값으로 반환한다. import json def lambda_handler(event, context): # TODO implement print(event) print('ProcessGreaterThan55 - Execution complete') return { 'statusCode': 200, 'body': json.dumps('ProcessGreaterThan55 - Execution complete') } -
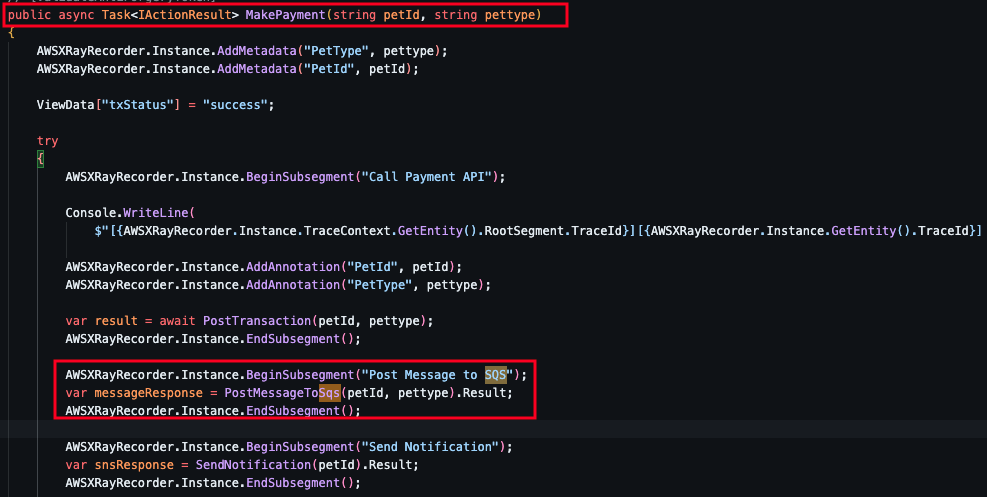
SQS 사용 이유? 서버서리스 메시지 큐 서비스로 본 예제에서는 비동기 작업 처리(입양)에 대한 부하 분산 및 메세지 처리 순서를 보장하기 위해 구성되었다. 메세지 큐 사용은 payment에서 사용되며 코드에서는 아래와 같이 입양시 SQS에 메세지를 날려 처리하도록 구성되어 있다.
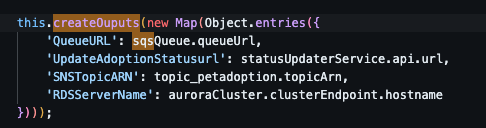
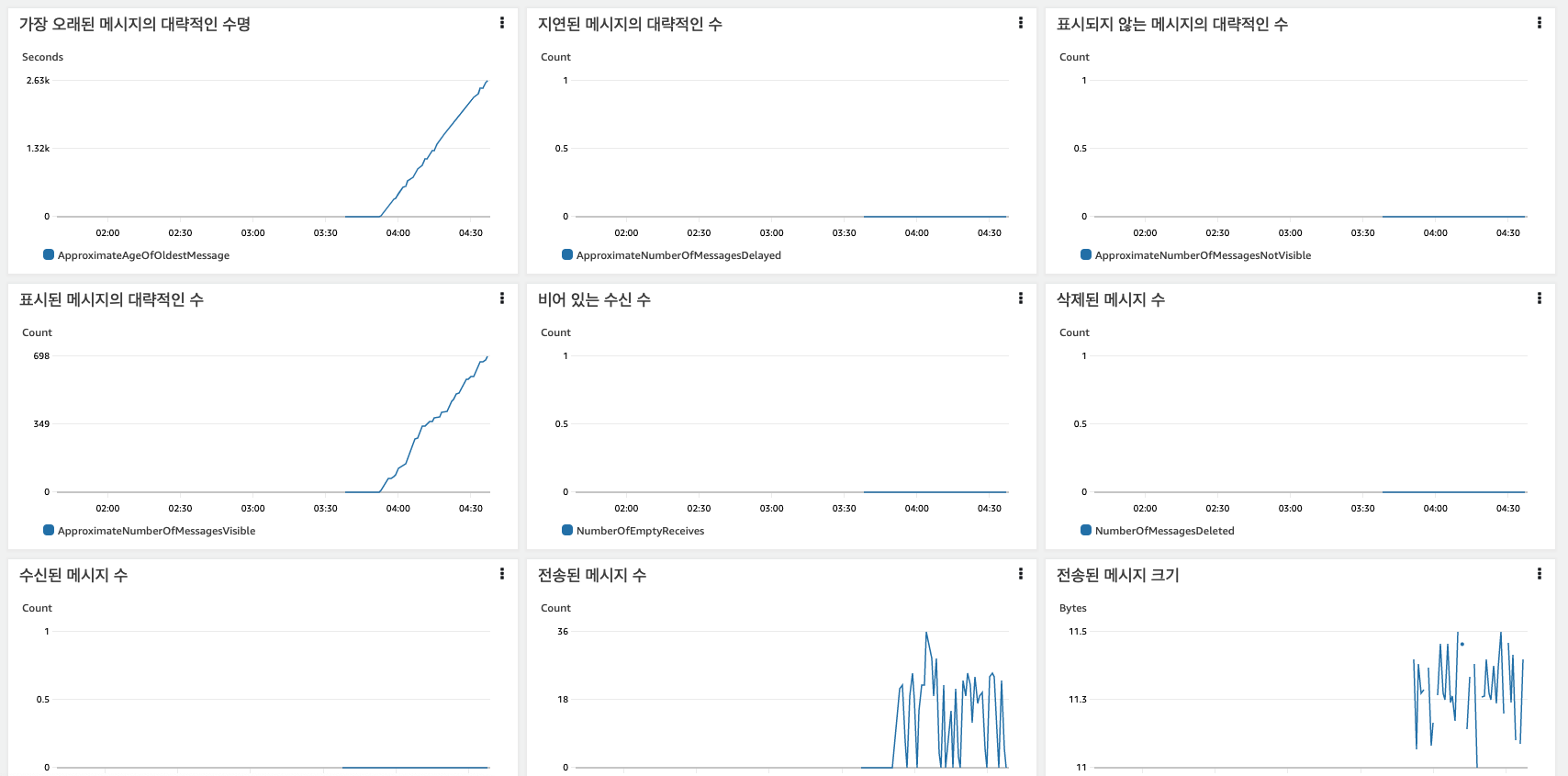
SQS를 사용하면, AWS 콘솔에서 메세지 큐에 대한 메트릭 정보를 확인할 수 있다. 각 메세지에 저장된 값도 확인할 수 있으면 좋겠지만,, 생산/처리 시스템으로 설계되어 있어 메세지 확인은 불가하다.
-
-
애플리케이션 API를 EKS 와 Fargate 로 구성한 이유?
Fargate와 EKS를 함께 사용하면 Kubernetes의 유연성과 Fargate의 서버리스 이점을 모두 활용할 수 있다고 한다. 함께 사용시 다음과 같은 이점이 있다.(참고 ChatGPT)
- 서버리스 컨테이너 운영: Fargate로 구성시 인프라 자원(서버/클러스터)에 대한 관리는 AWS에서 관리하며, 트래픽에 따라 자동으로 스케일링이 된다. 이에 따라 개발자는 컨테이너 인프라 관리에 신경 쓸 비용이 줄어 개발에 집중할 수 있게 된다.
- 비용 효율: Fargate는 실제 사용량에 따라 요금이 청구되므로, 사용하지 않는 컴퓨트 리소스에 대해 지불할 필요가 없다.
본 예제에서는 API 구성이 Frontend 부분만 EKS 관리형 노드의 Pod로 나머지 API는 Fargate로 구성되어 있다. 필자가 생각하건데 Frontend 부분만 EKS Pod로 사용한 이유는 전체 서비스의 첫 대문을 계속 운영하여 서비스에 대한 초기 로딩 지연시간을 업애기 위해 사용된 것 같고, 나머지 부분을 Fargate로 대체하여 추가 API 기능에 대해 초기 로딩 지연시간은 있지만, 비용을 절감할 수 있도록 구성한 것 같다.
-
AWS Lambda 와 EKS 를 같이 사용하는 이유?
결국 서버리스 컴퓨팅과 쿠버네티스(컨테이너화)의 차이점으로 작업이 이벤트이냐 아니냐에 따라 구성을 달리 한 것 같다. 본 예제에서의 람다 함수들은 트래픽 테스트를 위해 일정 시간 정보를 확인하는 함수와 입양 상태를 업데이트하는 함수로 구성되어 있어 있다. 이벤트 기반의 함수들에 대해 람다 함수들로 구성되어 있음을 확인할 수 있다.
아키텍처를 보면 람다와 동일한 서버리스 컴퓨팅인 Fargate를 사용한 것을 확인할 수 있다. 같은 서버리스 컴퓨팅 서비스이지만, 작업이 짧고 가벼운(호출/업데이트) 이벤트에 대해서는 람다로 구성하고 반대로 길고 컴퓨팅 자원이 무거운(조회) 이벤트에 대해서는 Fargate로 구성됨을 알 수 있다.
-
PetSearch-API에 S3 하고 dynamodb를 사용한 이유?
이미지를 저장하고 검색하는 경우, S3 스토리지를 사용하는 것이 일반적이다. 그러나 사용자 정보, 상품 카탈로그, 게임 상태 등과 같은 구조화된 데이터를 빠르게 검색하고 조작할 필요가 있을 때는 DynamoDB가 더 적합하다. 본 예제에서는 이 둘을 결합하여 애완동물 이미지 파일을 S3에 저장하고, 해당 이미지의 메타데이터(예: 펫 이름, 입양 상태)를 DynamoDB에 저장하도록 구성되어 있다. 이렇게 하면 빠르고 효율적인 검색을 통해 필요한 이미지를 신속하게 찾을 수 있다.
S3 콘솔에서는 다음과 같이 이미지 파일들을 확인할 수 있다.
다음 코드는 람다 서비스의 PetAdoptionStauteUpdate 코드이다. 코드를 보면 입양이 완료되면 dynamodb에 저장된 애완동물 메타데이터(availability) 를 업데이트하여 애완 동물의 입양 상태를 업데이트하도록 구성되어 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37"use strict"; // asset-input/index.js var AWSXRay = require("aws-xray-sdk"); var AWS = AWSXRay.captureAWS(require("aws-sdk")); var documentClient = new AWS.DynamoDB.DocumentClient(); exports.handler = async function(event, context, callback) { var payload = JSON.parse(event.body); var availability = "yes"; if (payload.petavailability === void 0) { availability = "no"; } var params = { TableName: process.env.TABLE_NAME, Key: {12 "pettype": payload.pettype, "petid": payload.petid }, UpdateExpression: "set availability = :r", ExpressionAttributeValues: { ":r": availability }, ReturnValues: "UPDATED_NEW" }; await updatePetadoptionsTable(params); # 업데이트 부분 console.log("Updated petid: " + payload.petid + ", pettype: " + payload.pettype + ", to availability: " + availability); return { "statusCode": 200, "body": "success" }; }; async function updatePetadoptionsTable(params) { await documentClient.update(params, function(err, data) { if (err) { console.log(JSON.stringify(err, null, 2)); } else { console.log(JSON.stringify(data, null, 2)); } }).promise(); } -
PayForAdoptions-API 에 API gateway를 사용한 이유 ?
WS Lambda 앞에 API Gateway를 연결하는 것은 웹 또는 모바일 애플리케이션에서 서버리스 백엔드를 구성하는 일반적인 패턴이다. 람다에서는 자체적으로 HTTP(S) 엔드포인트를 제공하기 때문이다. 이렇게 하면 AWS Lambda를 사용하여 복잡한 백엔드 로직을 처리하고, API Gateway를 사용하여 HTTP 요청을 라우팅하고 보안을 관리할 수 있다.
예제 배포
예제 배포는 AWS CDK로 배포한다. CDK 는 AWS 서비스에 대한 IaS 로 코드를 통해 AWS 서비스를 배포 할 수 있다. 배포를 위한 명령어로는 다음과 같다.
|
|
Trace (트레이싱)
트레이싱은 분산 시스템에서 요청의 생애 주기를 추적하는 기술로, 이를 통해 서비스 간 상호 작용의 가시성을 제공하고 문제를 진단하는 데 도움을 주는 기능이다. 트레이싱은 로그, 메트릭, 분산 트레이싱의 세 가지 관측 가능한 신호 중 하나로 관측 시스템에 큰 축을 담당하고 있다.
트레이싱은 분산 시스템 및 마이크로서비스에서 기능이 크게 부각되는데 해당 시스템에서는 한 요청이 여러 서비스를 거쳐 처리되므로 문제가 발생했을 때 문제가 발생했는 지 파악하기가 어렵다. 이를 해결하기 위해 트레이싱은 서비스간의 요청마다 고유한 ID를 부여하여 이벤트를 발생시킬 때마다 이벤트의 시간 시간과 끝시간을 레이턴시를 파악한다.
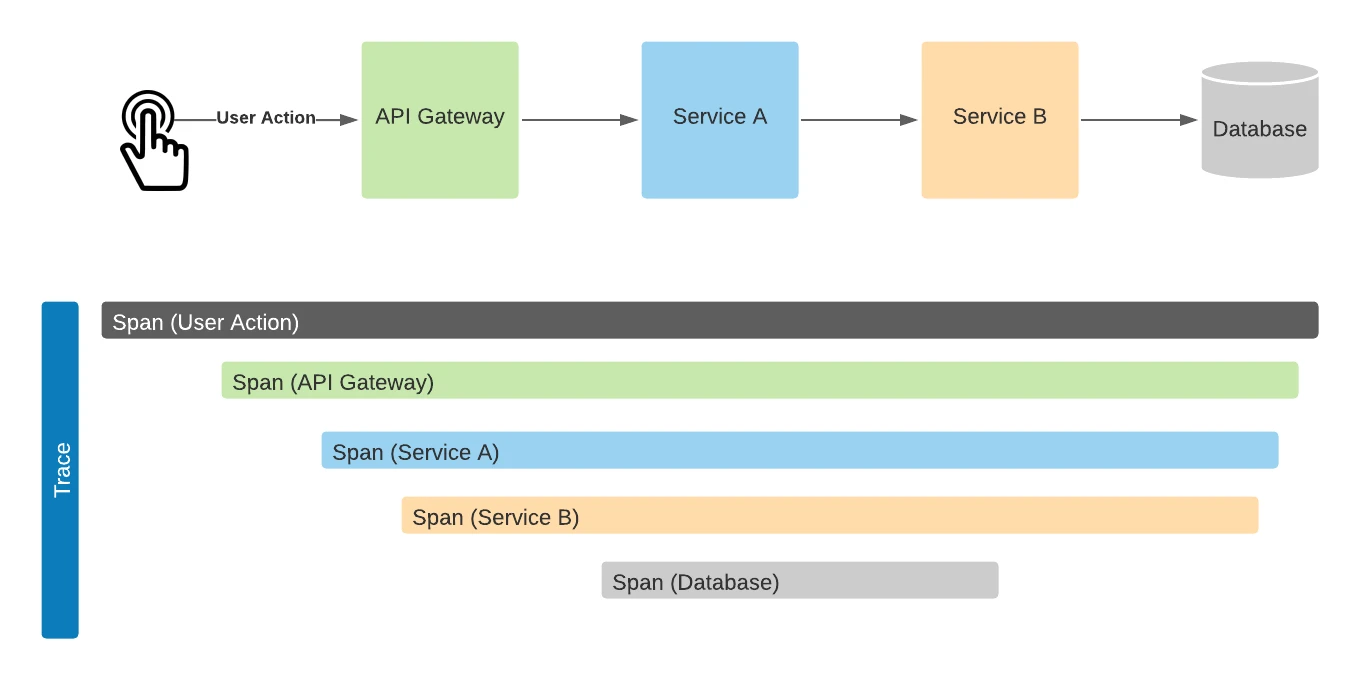
https://www.dynatrace.com/news/blog/open-observability-distributed-tracing-and-observability/
X-Ray
AWS 에서는 X-ray라는 서비스를 통해 트레이싱 기능을 제공한다. 워크샵에서는 X-ray를 사용하기 위한 코드 삽입 및 X-ray 파드가 배포되어 있는 상태이다. 본 블로그 글에서는 X-ray 설치는 스킵하고 트레이싱에 대한 기능 위주의 글을 작성할 예정이다.
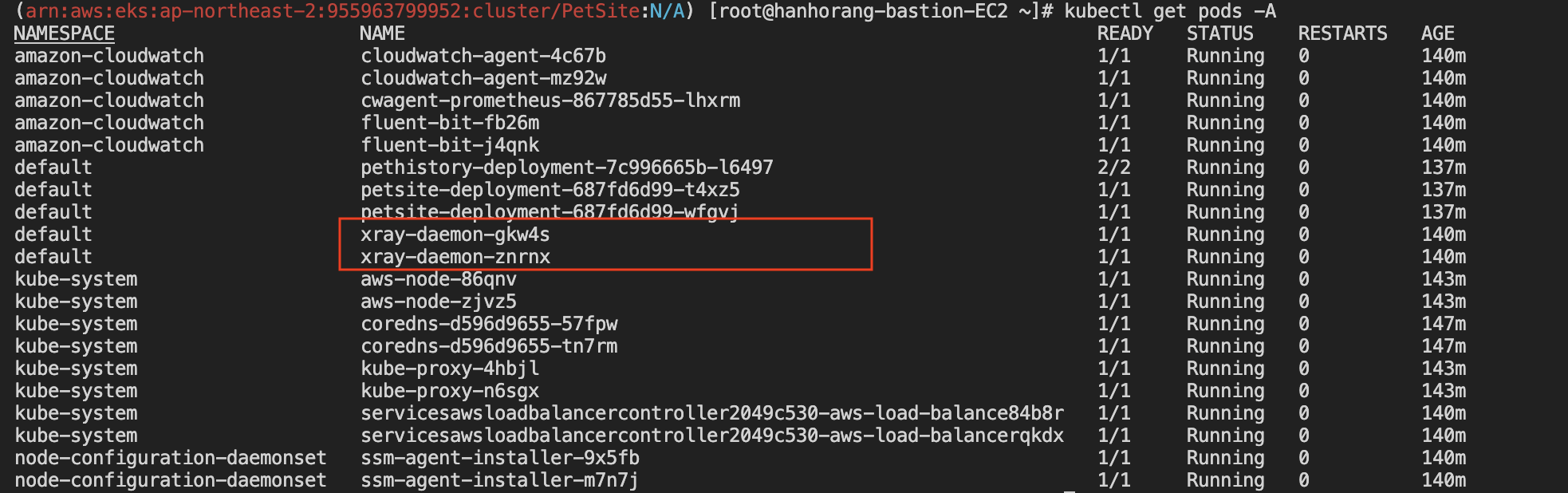
여기서 배포된 Xray-daemon 파드가 정보를 받아 AWS X-ray에 제공한다고 보면 이해가 쉽다.

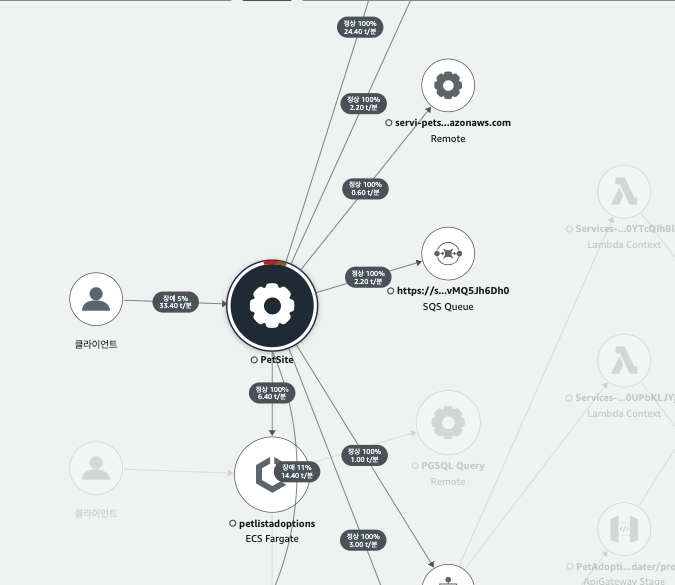
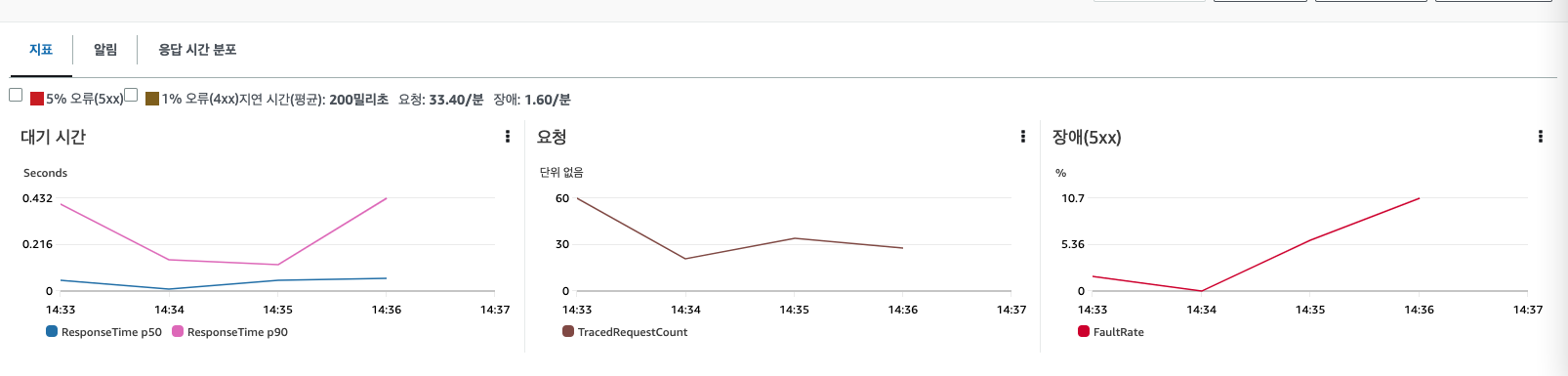
제공한 트레이싱 데이터들은 AWS 콘솔의 X-ray에서 확인할 수 있다. 예제 마이크로서비스에 대한 응답 시간과 메트릭(대기 시간, 요청, 장애) 를 한눈에 확인할 수 있다.
X-ray 기능 확인하기
워크샵 내용을 토대로 X-ray 기능를 통해 확인하여 트레이싱 기능을 이해해보자. 가장 먼저, AWS 콘솔에 접근하면 다음과 같이 응답 시간을 한 눈에 확인할 수 있다. 먼저, 밑의 그림 처럼 장애난 부분의 화살표를 클릭하여 각 서비스 간의 응답 시간 및 에러 원인을 찾을 수 있다.
에러 트레이싱하기
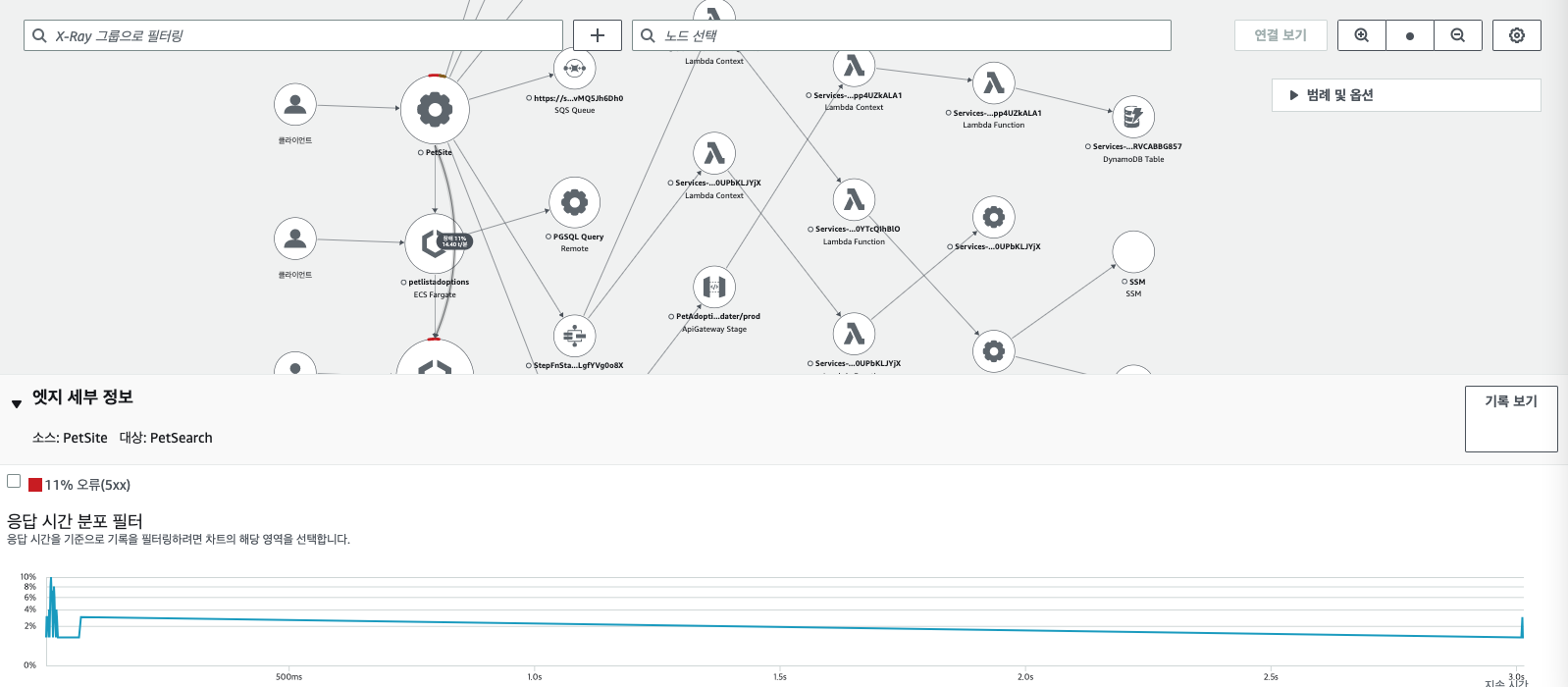
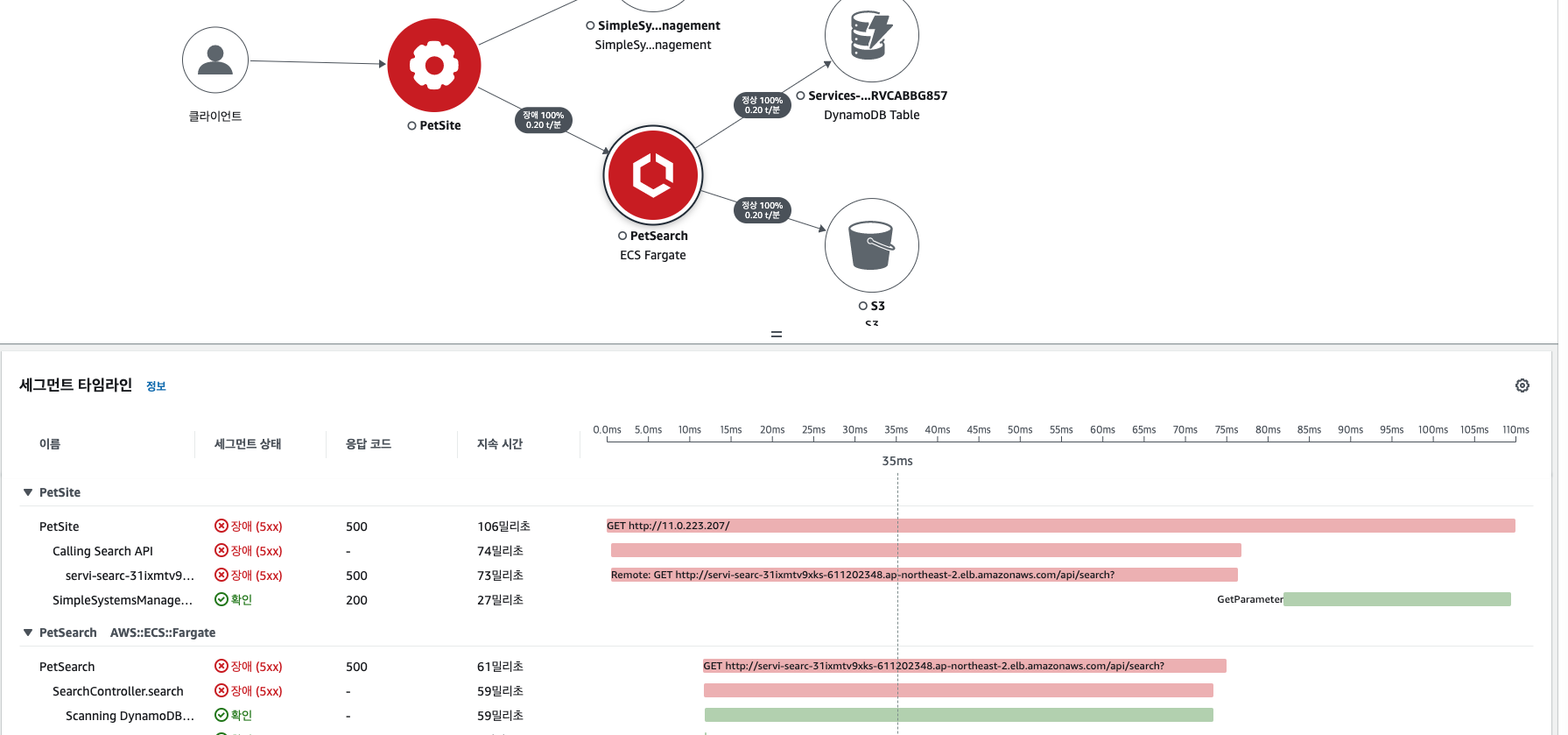
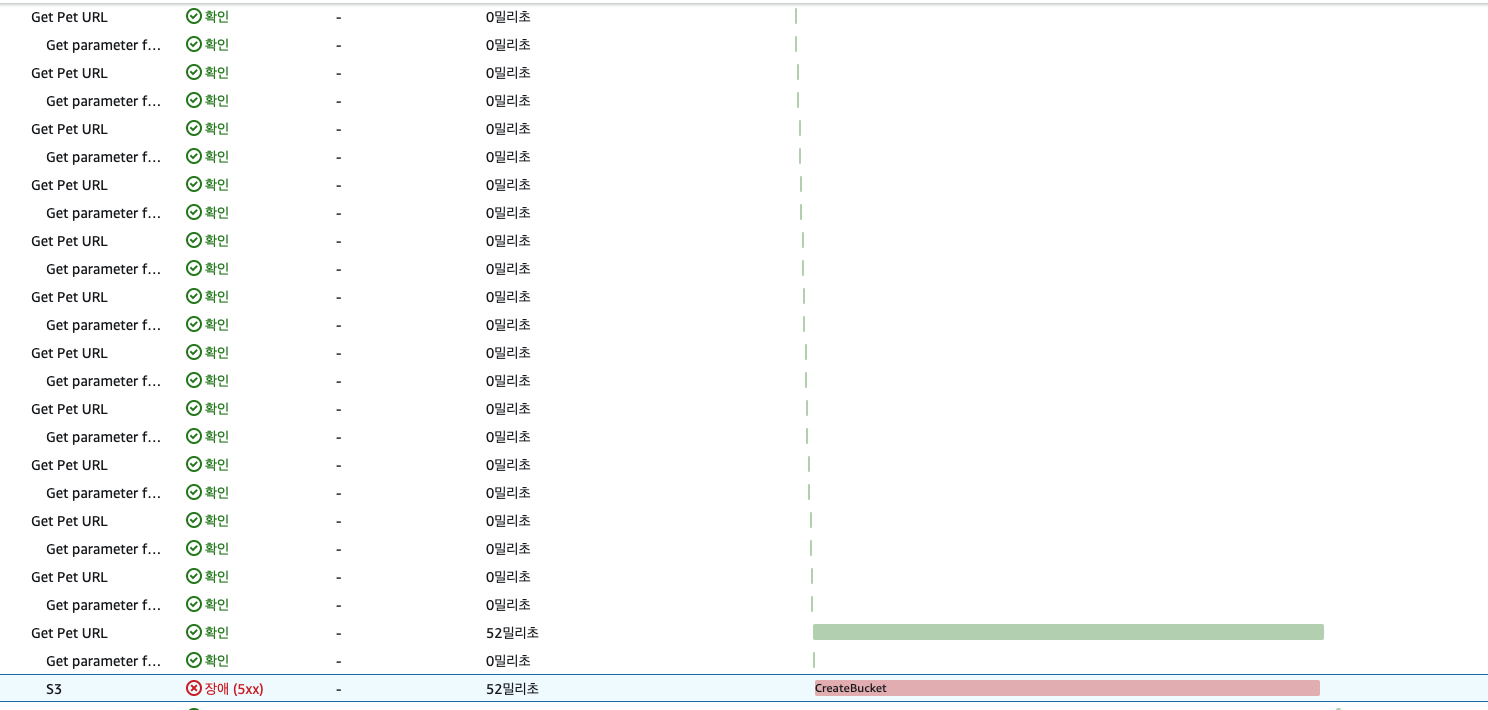
트레이싱 비교를 통해 원인 분석하기
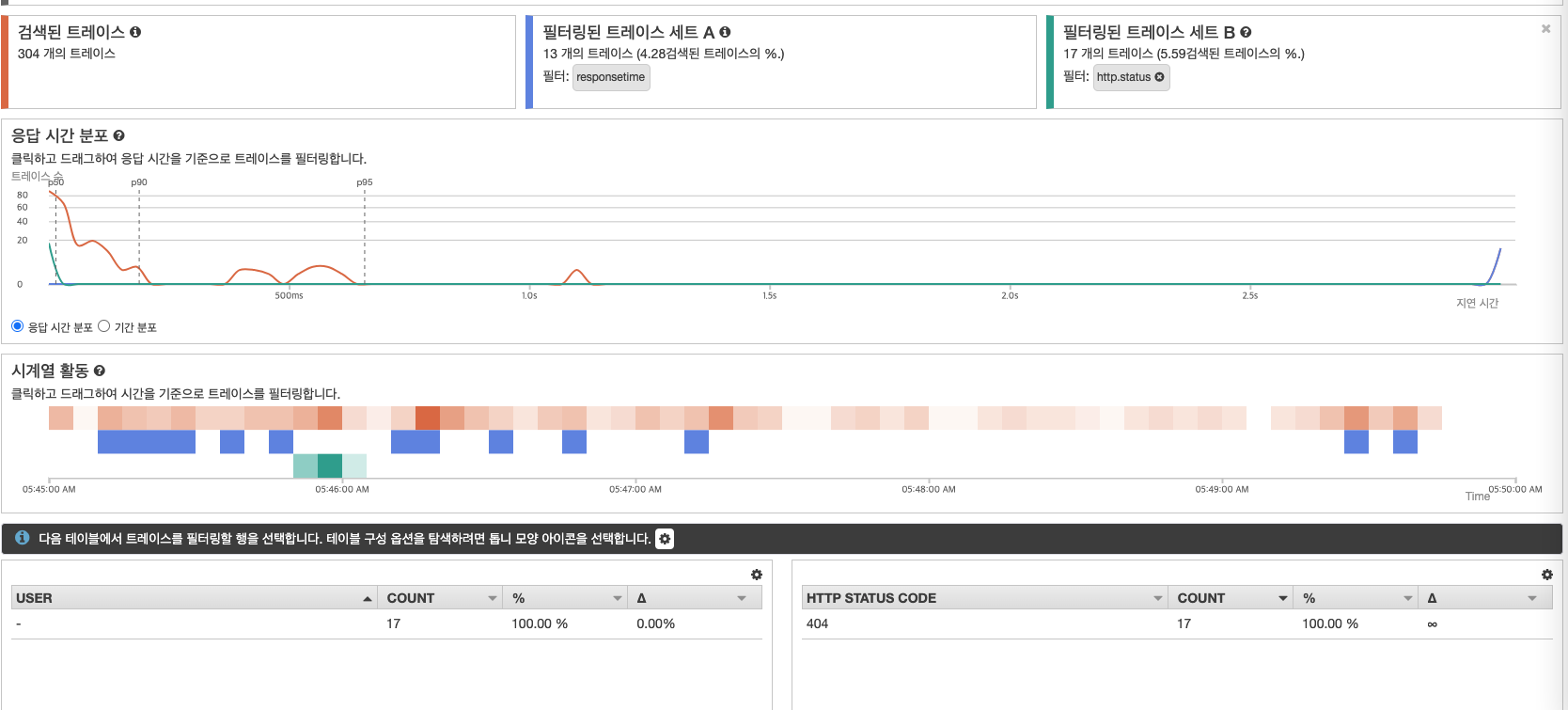
다음은 X-ray Anlytics 의 기능으로 트레이스 데이터간 비교하여 문제 해결에 도움을 주는 기능을 확인하자. [AWS 콘솔] → [X-ray Anlytics] 에 접근하면 다음과 같이 트레이스 데이터를 확인할 수 있다. 다음 그림과 같이 응답 시간 분포에서 3초 이상의 데이터를 확인하여 분석을 위해 드래그를 통해 상세 정보를 확인하면 특정 API (조회)시 발생하는 것을 확인할 수 있다.
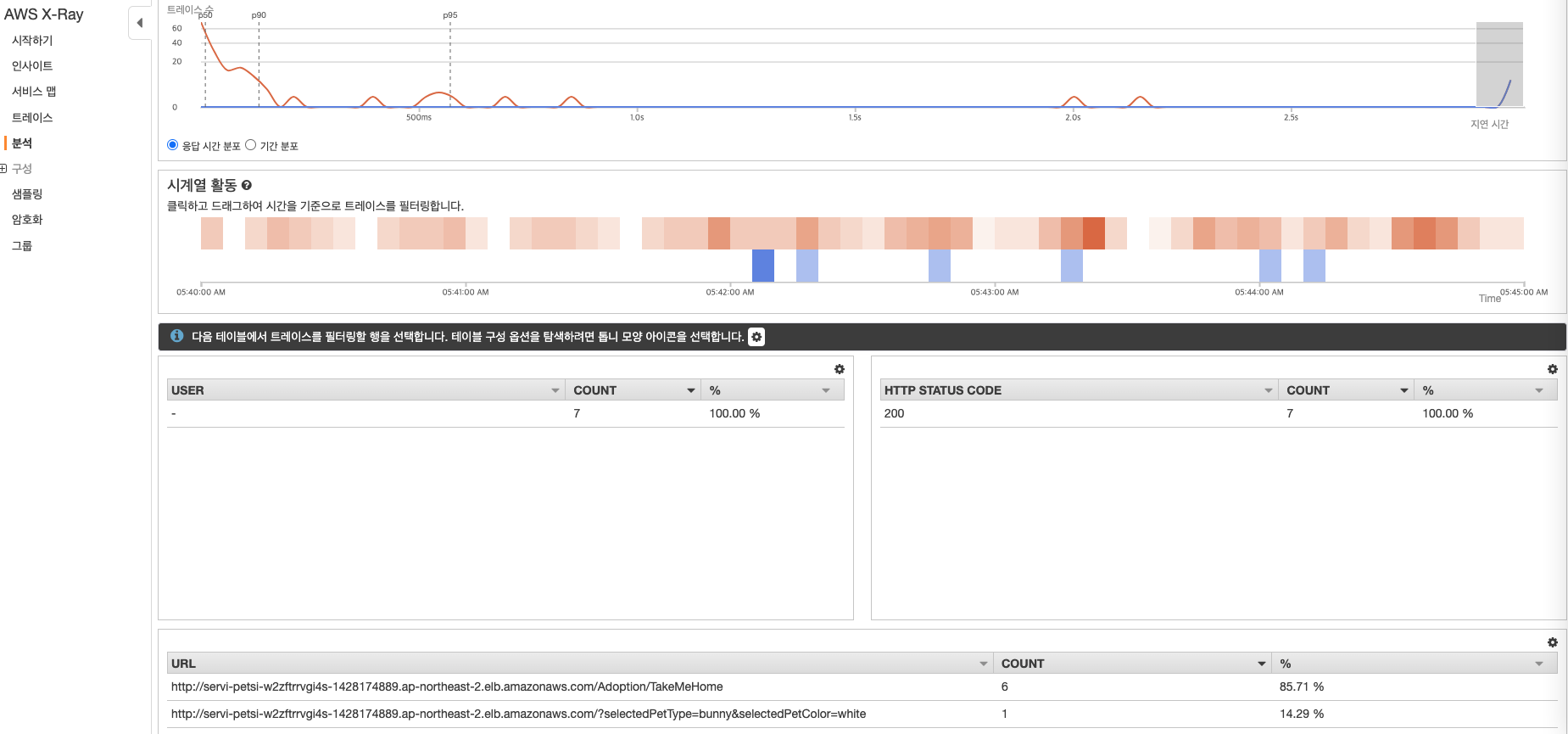
특정 API 에 대한 응답 시간이 늦춰짐과 동시에 대한 원인 분석으로 해당 API가 실패했을 때 응답 시간이 3초이상 되는 지 확인할 수 있다. 아래 그림에서 필터링된 트레이스 세트 B를 클릭하고 HTTPS Stateus code를 클릭하면 트레이스 데이터간 비교가 가능하다. 아래 결과를 분석하면 실패했을 때는와 응답 시간에 대한 연관 관계는 없는 것을 확인할 수 있다.
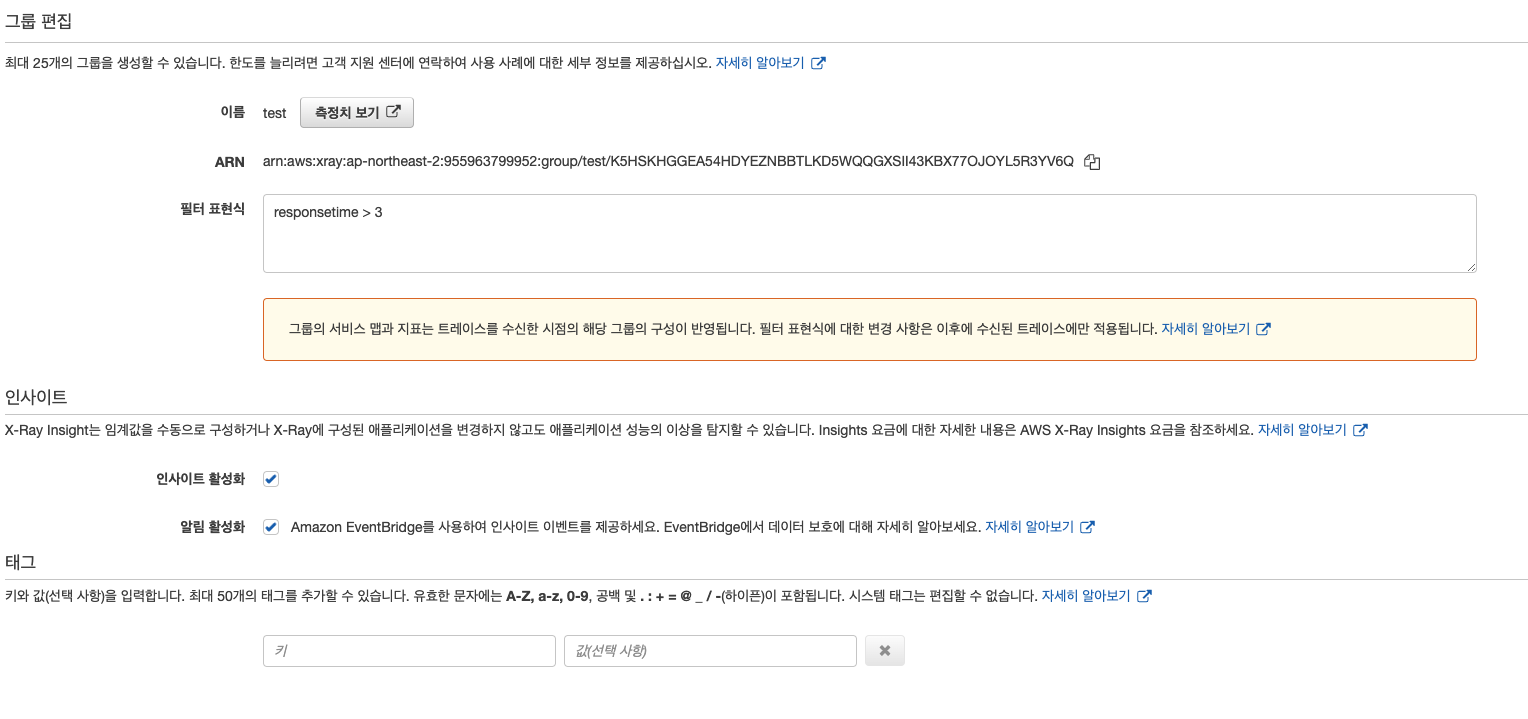
알람 구성
트레이싱 데이터에 대해 알람 구성이 가능하다. X-ray 의 그룹에 접근하여 필터 표현식을 통해 메트릭 생성이 가능하기 때문이다. 아래 예제는 응답 시간이 3초 이상에 대한 메트릭을 생성하여 Cloudwatch에서 해당 메트릭을 확인하는 예제이다.
사용 케이스를 통한 트레이싱 이해하기
워크샵에서는 시스템 에러에 대한 트러블슈팅 과정으로 여러 사용 케이스를 제공한다. 실제 AWS 기반의 애플리케이션 운영시 트러블슈팅 과정에 도움이 되는 시나리오라 생각되어 구성 내용을 간략하게 정리하여 공유한다.
트래픽 발생에 따른 트러블 슈팅
예제 애플리케이션 사이트에 과부하를 줘서 생기는 트러블슈팅 과정을 먼저 살펴보겠다. 다음의 명령어를 통해 과부화를 주자.
|
|
과부화를 주면 아래 그림의 DynamoDB에 알람 표시가 나온 것을 확인할 수가 있다. 알람을 확인하면 해당 DB의 읽기 용량이 초과되었음을 확인할 수 있다.
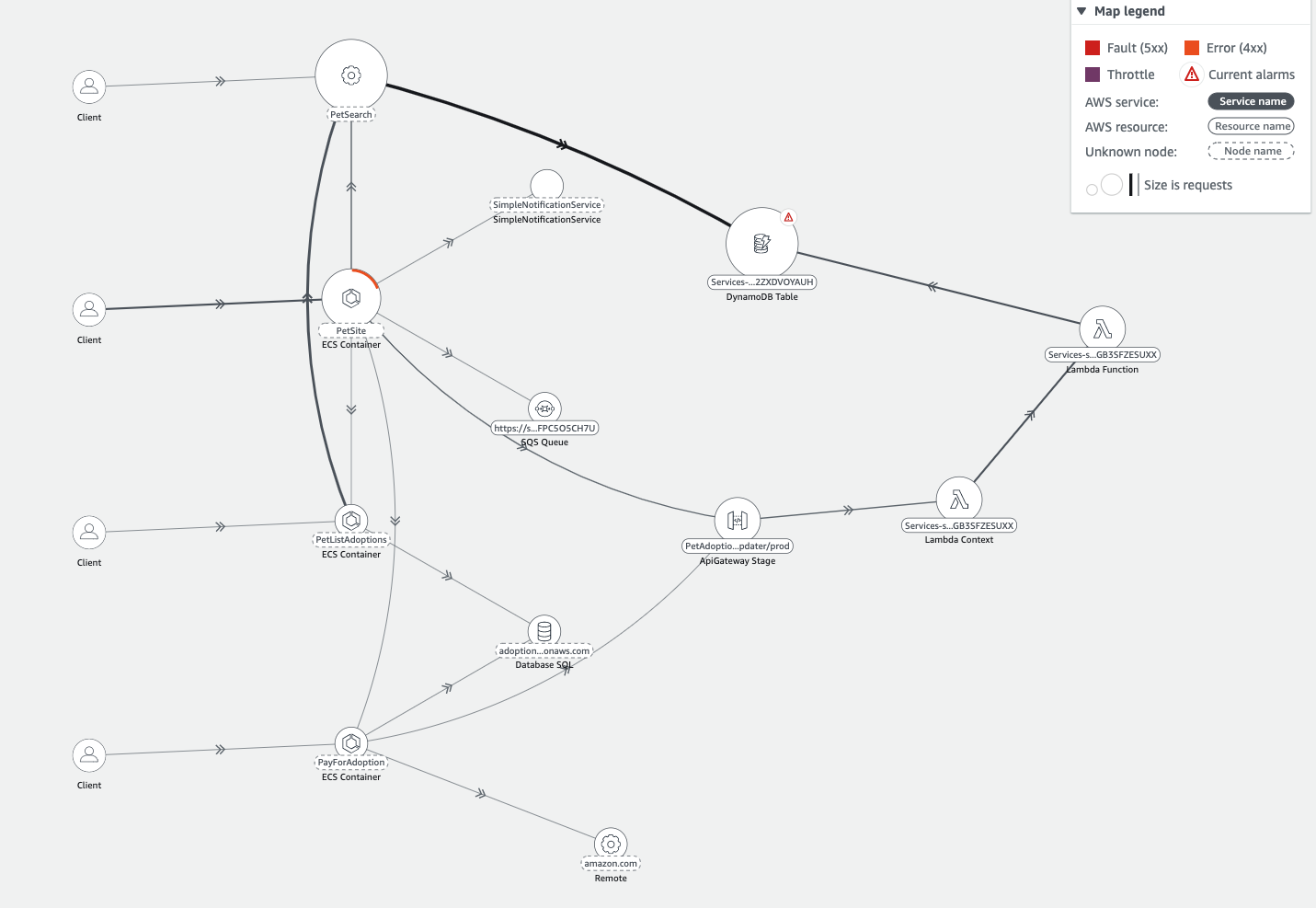
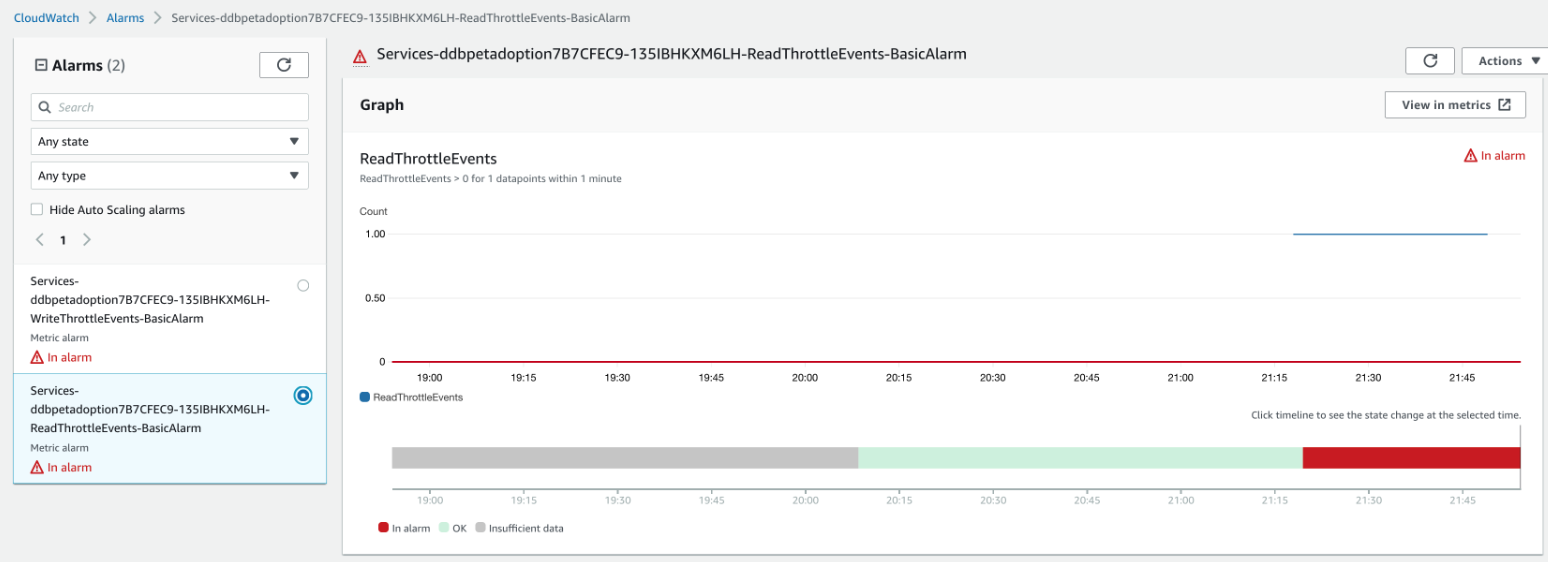
해결 방법은 간단하다. DynamoDB 테이블이 프로비저닝된 용량 모드로 요청이 제한되었기 때문에 온디맨드 용량 모드 옵션을 변경하면 처리가 된다. 옵션 명령어는 다음과 같다.
|
|
메모리 문제 발생시 트러블슈팅
다음은 메모리를 비롯한 인프라에 대한 문제 발생시 트러블슈팅 하는 과정이다. 인프라 자원의 문제가 생기면 애플리케이션에 대한 에러가 발생할 것이다.
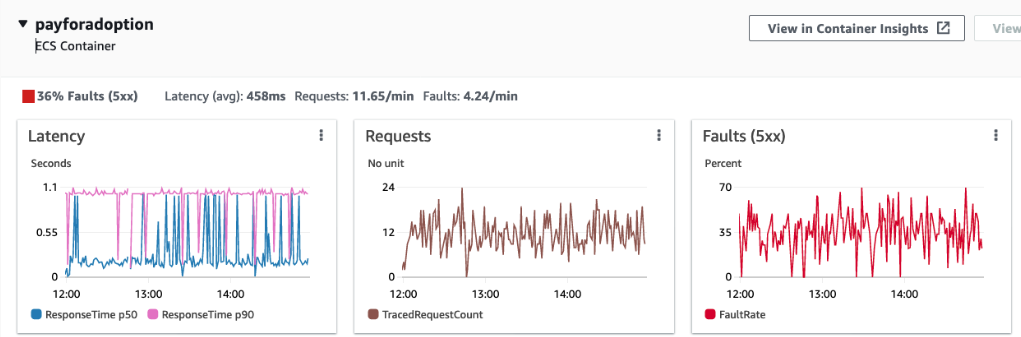
원인 분석으로 X-ray에서는 필터링 기능을 통해 에러 통신 값에 따른 트레이싱 정보를 확인할 수 있다.
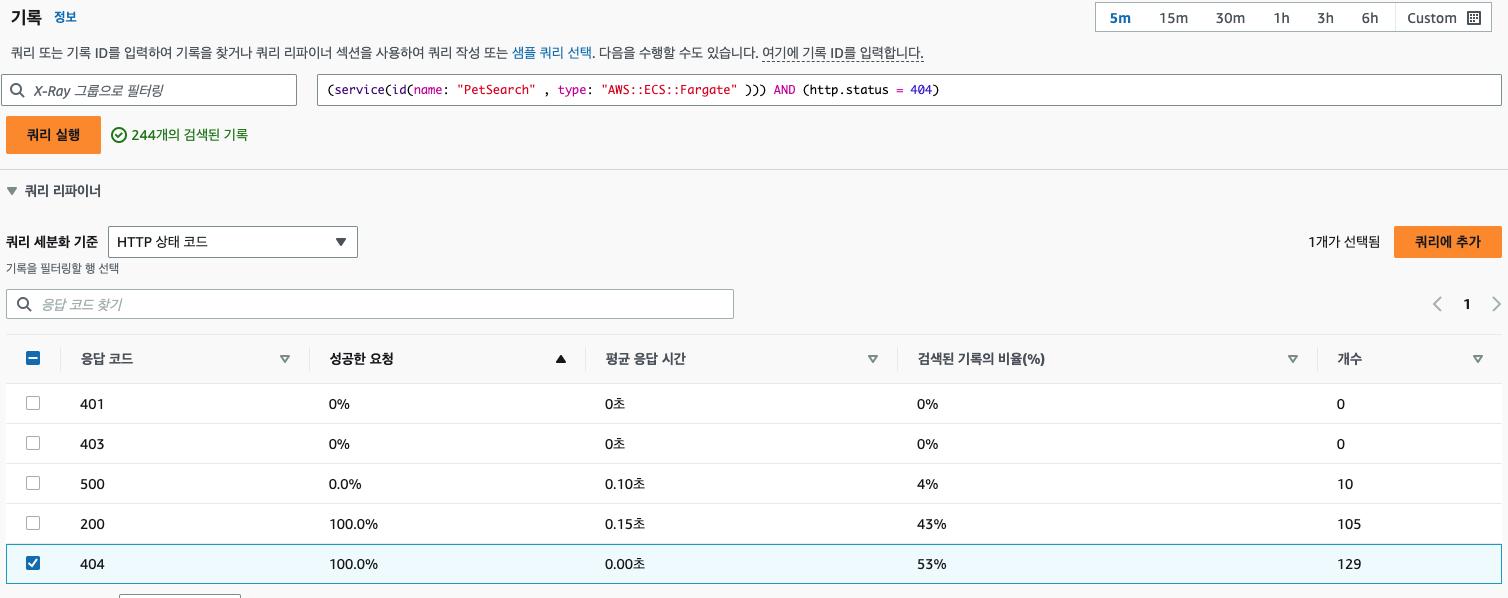
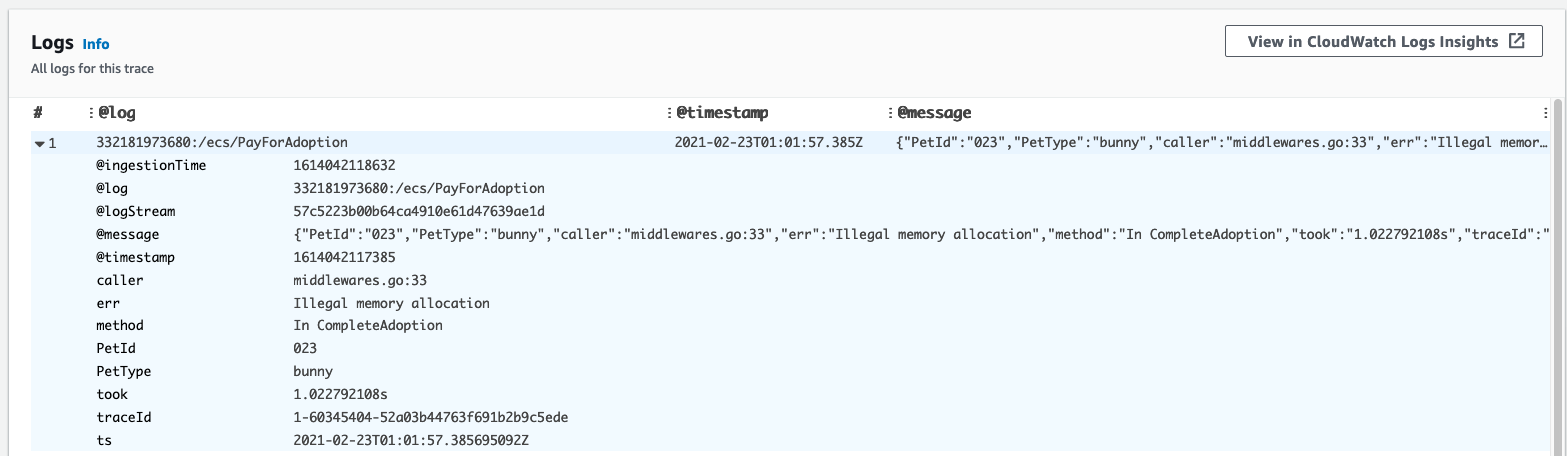
트레이싱 데이터를 클릭하면 각 요청에 대한 상세 정보를 확인할 수 있다. 데이터 내에서는 각 요청에 대한 로그도 확인할 수 있는 데 밑의 로그 기록처럼 메모리 관리 부분에 문제가 생긴 것을 확인할 수 있다.
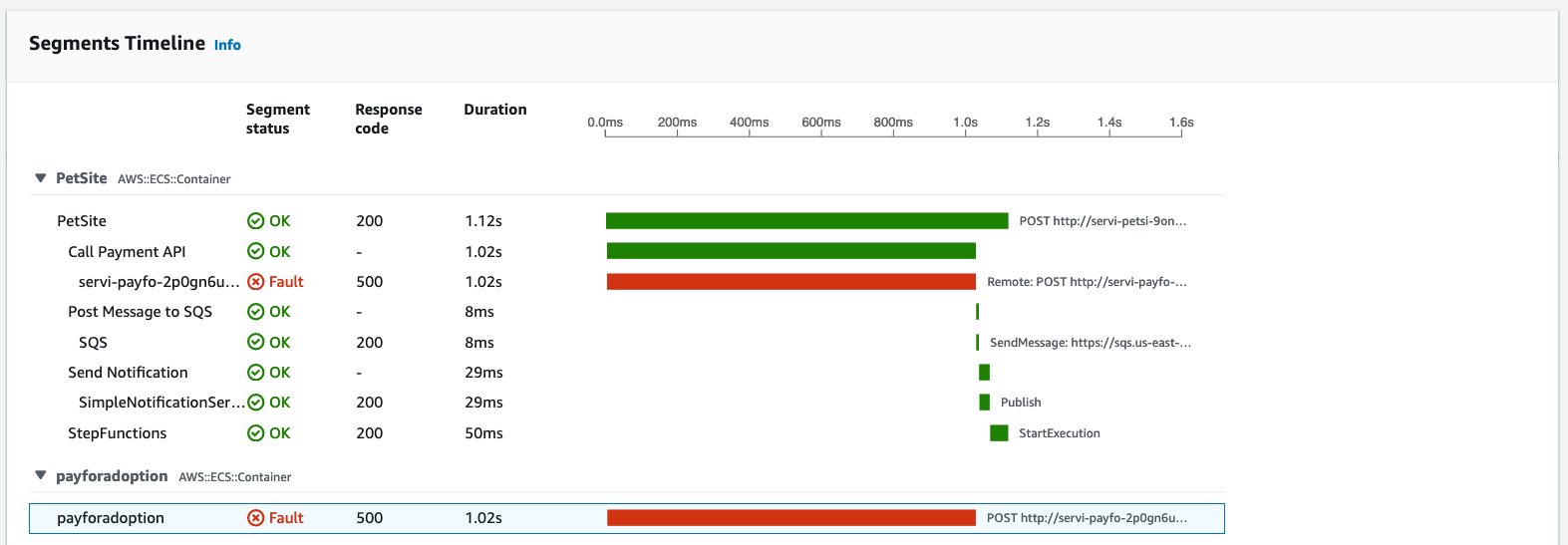
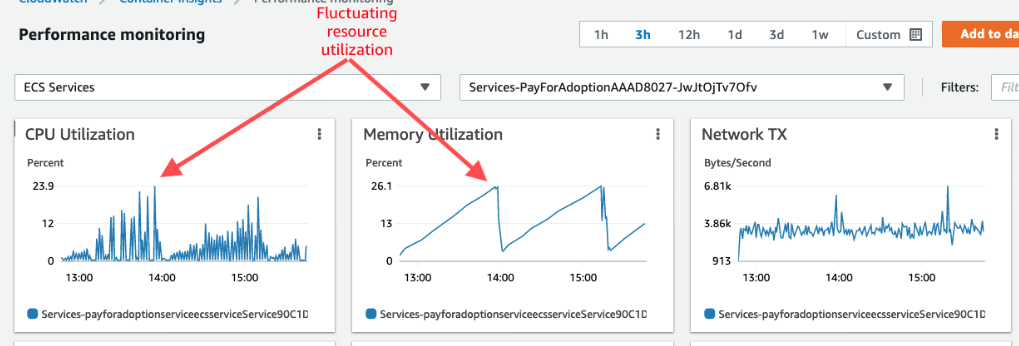
이를 증명하기 위해 클라우드워치에서 메모리 및 CPU 메트릭을 확인하면 다음과 같이 인프라 자원에 피크가 생긴 것을 확인할 수 있다.